05-线性代数
本节目录
1. 线性代数基础知识
这部分主要是由标量过渡到向量,再从向量拓展到矩阵操
分类标签归档:深度学习
本文是CVPR 2017的文章,提出了残差注意力网络(Residual attention network),这是一种使用注意力机制的卷积神经网络,可以以端到端的训练方式与最新的前馈网络体系结构结合。残差注意力网络是通过堆叠注意力模块构建的,这些模块会生成注意力感知功能。每个注意力模块被分为两个分支:掩码分支和主干分支。主干分支进行特征处理,可以适应任何先进的网络结构。随着模块的深入,来自不同模块的注意力感知功能会自适应地变化。在每个注意模块内,自下而上、自上而下的前馈结构用于将前馈展开并将反馈注意过程反馈到单个前馈过程中。作者提出了注意力
首先画一个简单的人工智能地图:

x轴表示不同的模式or方法:最早的是符号学,接下来是概率模型,之后是机器学习
y轴表示可以达到的层次:由底部向上依次是
感知:
Bert把中文文本进行了embedding,得到每个字的表征向量
dense操作得到了每个文本文本对应的未归一化的tag概率
CRF在选择每个词的tag的过程其实就是一个最优Tag路径的选择过程
CRF层能从训练数据中获得约束性的规则
比如开始都是以xxx-B,中间都是以xxx-I,结尾都是以xxx-E
比如在只有label1-I
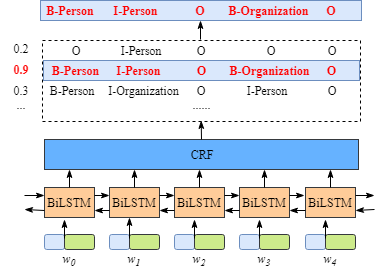
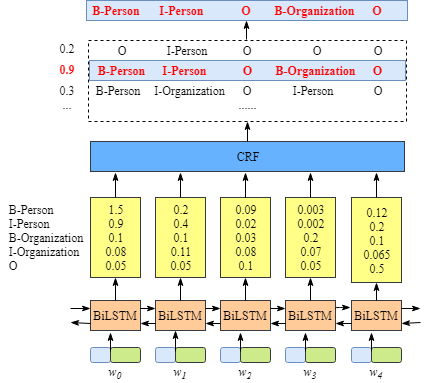
CRF层的输入是:每个词预测对应每个标签的分数 CRF层的输出是:每个可能的标注序列,并选择得分最高的序列作为最终结果; 如果没有CRF层的帮助,仅BiLSTM的话,模型只会选择每个词对应标签最大的概率作为输出,可能会出现I-Persion
语音合成,又称文语转换(Text To Speech, TTS),是一种可以将任意输入文本转换成相应语音的技术。 Tacotron2 论文地址:Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
传统的语音合成系统通常包括前端和后端两个模块。前端模块主要是对输入文本进行分析,提取后端模块所需要的语言学信息,对于中文合成系统而言,前端模块一般包含文本正则化、分词、词性预测、多音字消歧、韵律预测等子模块。后端模块根据前端分析结果,通过一定的方法生成语音波形,后端系统一
本文是对CRF基本原理的一个简明的介绍。 我们先来对比一下普通的逐帧softmax和CRF的异同。
CRF主要用于序列标注问题,可以简单理解为是
给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
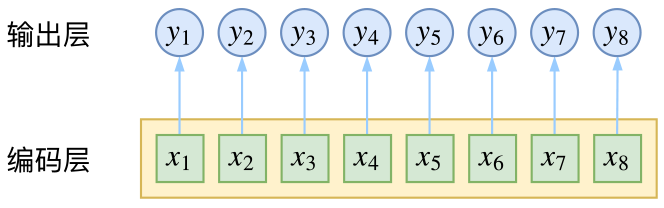
逐帧softmax并没有直接考虑输出的上下文关联
然而,当我们设计标签时,比如用s、b、m、e的4个标签来做字标注法的分词,目标输出序列本身会带有一些上下文关联,比如s后面就不能接m和e,等等。逐标签softmax并没有考虑这种输出层面的上下文关联,所以它意味着把这些关联放到了编码
 image.png
论文地址:https://arxiv.org/pdf/1907.11692.pdf
论文标题:
RoBERTa: A Robustly Optimized BERT Pretraining A pproach
一个强力优化的BERT预训练方法。
image.png
论文地址:https://arxiv.org/pdf/1907.11692.pdf
论文标题:
RoBERTa: A Robustly Optimized BERT Pretraining A pproach
一个强力优化的BERT预训练方法。
语言模式预训练已经带来了显著的性能提升,但仔细比较不同方法是一个挑战。训练的计算成本很高,通常是在不同大小的私有数据集上进行的,我们将展示,超参数选择对最终结果有重大影响。我们对BERT 预训练进行了一项复制研究,仔细测量了许多关键超参数和训练数据大小的影响。 我们发现,BERT的训练明显不足,可以与发布后的每个模型的
上两篇Attention机制详解(一)——Seq2Seq中的Attention, Attention机制详解(二)——Self-Attention与Transformer主要回顾了Attention与RNN结合在机器翻译中的原理以及self-attention模型,这一篇准备分类整理一下Attention模型的各种应用场景,主要参考资料为谷歌研究组和Yoshua Bengio组的论文。
之前已经见过Attention模型对于机器翻译(Attention is All you need)有非常很好的效果,那么在自然语言处理方面Attention模型还有哪些其他应用呢?我们通过总结以
上一篇Attention机制详解(一)——Seq2Seq中的Attention回顾了早期Attention机制与RNN结合在机器翻译中的效果,RNN由于其顺序结构训练速度常常受到限制,既然Attention模型本身可以看到全局的信息, 那么一个自然的疑问是我们能不能去掉RNN结构,仅仅依赖于Attention模型呢,这样我们可以使训练并行化,同时拥有全局信息? 这一篇就主要根据谷歌的这篇Attention is All you need论文来回顾一下仅依赖于Attention机制的Transformer架构,并结合Tensor2Tensor源代码进行解释。
先来看一个翻