上两篇Attention机制详解(一)——Seq2Seq中的Attention, Attention机制详解(二)——Self-Attention与Transformer主要回顾了Attention与RNN结合在机器翻译中的原理以及self-attention模型,这一篇准备分类整理一下Attention模型的各种应用场景,主要参考资料为谷歌研究组和Yoshua Bengio组的论文。
自然语言处理
之前已经见过Attention模型对于机器翻译(Attention is All you need)有非常很好的效果,那么在自然语言处理方面Attention模型还有哪些其他应用呢?我们通过总结以下几篇论文来了解以下:
Universal Transformers
这篇文章主要是结合了Transformer结构与RNN中循环归纳的优点,使得Transformer结构能够适用更多自然语言理解的问题。其改进的结构如下
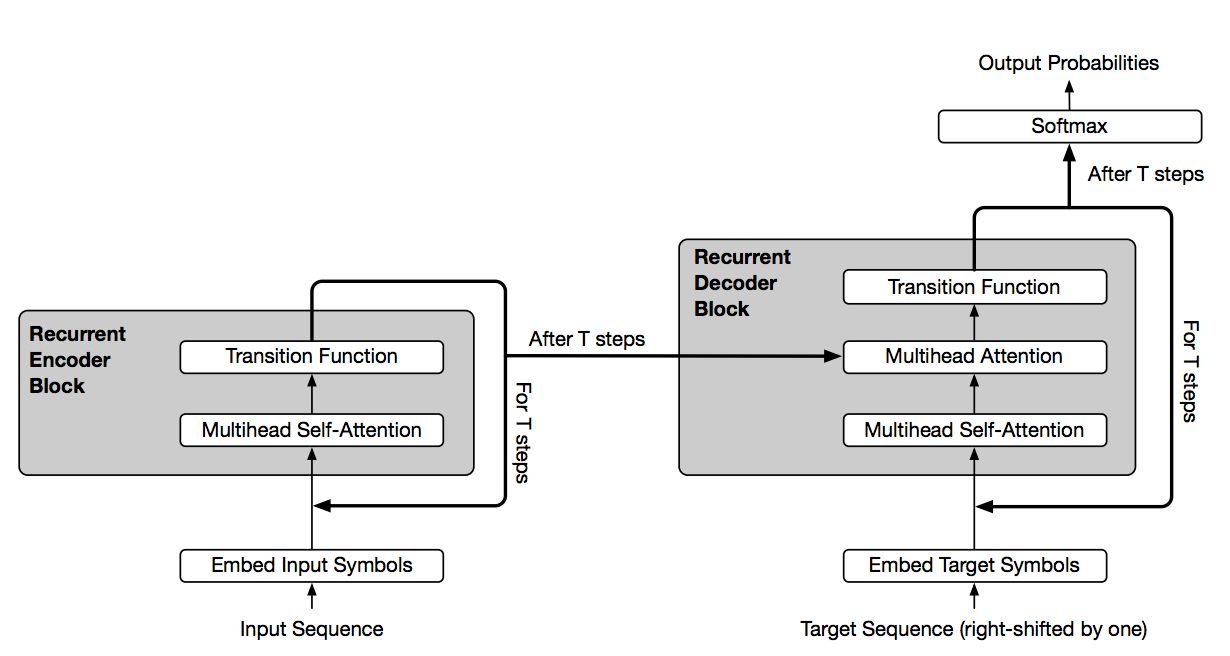 可以看到,通过引入Transition Function,我们对Attention可以进行多次循环。这一机制被有效的应用到诸如问答,根据主语推测谓语,根据上下填充缺失的单词,数字字符串运算处理,简易程序执行,机器翻译等场景。
可以看到,通过引入Transition Function,我们对Attention可以进行多次循环。这一机制被有效的应用到诸如问答,根据主语推测谓语,根据上下填充缺失的单词,数字字符串运算处理,简易程序执行,机器翻译等场景。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
这也是最近自然语言处理领域比较火的文章,打破了多项benchmark,主要是利用双向Transformer进行预处理,得到包含有上下文信息的表示,这一表示可进一步用来fine-tune很多种自然语言处理任务。下图是BERT模型(双向Tansformer结构)与OpenAI GPT(单向Transformer结构)与ElMo(双向独立LSTM最终组合的结构)的对比。
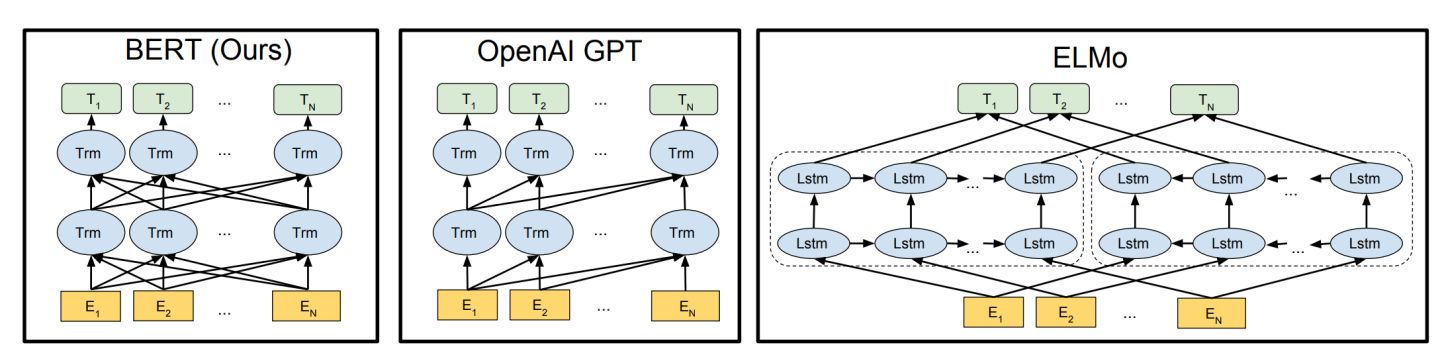 BERT的表示进行fine-tuning后,对于GLUE Benchmark(主要包含MNLI,RTE:比较两个句子的语义关系,QQP:判别Quora上两个问题相似度,QNLI:问答,SST-2:情感分析,CoLA:语句合理性判别,STS-B, MRPC:句子相似度判别),SQuAD(问答),NER(命名实体识别)等都有极大的提高。将来,可能BERT pre-train在自然语言处理领域就会像VGG, ResNet, Inception等在图像识别里的作用而成为预处理的标配。
BERT的表示进行fine-tuning后,对于GLUE Benchmark(主要包含MNLI,RTE:比较两个句子的语义关系,QQP:判别Quora上两个问题相似度,QNLI:问答,SST-2:情感分析,CoLA:语句合理性判别,STS-B, MRPC:句子相似度判别),SQuAD(问答),NER(命名实体识别)等都有极大的提高。将来,可能BERT pre-train在自然语言处理领域就会像VGG, ResNet, Inception等在图像识别里的作用而成为预处理的标配。
Generating Wikipedia by Summarizing Long Sequences
文章生成:通过处理若干篇源文章,提取有效信息,再用Transformer Decoder合成一篇类似于Wikipedia风格的文章,这个模型以后加以改善可以极大的方便人们获取有效信息。
图像处理及合成
其实最早Attention模型是先在图像处理领域得到应用,后来拓展到自然语言处理领域,例如这一篇
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
就是利用Attention机制进行Image Caption(将图像翻译为文字表述)

Image Transformer
利用Attention机制进行图像合成,如将局部图像补全:
 通过低分辨率的图像还原高分辨率图像
通过低分辨率的图像还原高分辨率图像
 由于Image Transformer模型训练的稳定性,很有可能代替GAN成为图像生成任务的首选。
由于Image Transformer模型训练的稳定性,很有可能代替GAN成为图像生成任务的首选。
其他
这里再列出一些综合或其他方面的应用
One Model To Learn Them All
采用多适应性的模型架构希望一个模型可以处理多领域的问题。其模型结构如下所示
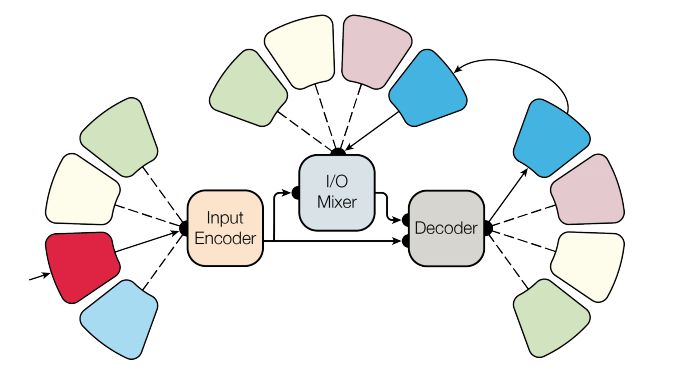 该论文中处理了语言文字、图像、声音和分类数据,虽然和state-of-the-art还不能相比,但也不失为一种泛机器学习的有意思的尝试。
该论文中处理了语言文字、图像、声音和分类数据,虽然和state-of-the-art还不能相比,但也不失为一种泛机器学习的有意思的尝试。
Neural Attentive Session-based Recommendation
利用Attention模型处理用户session中的序列信息进行相关推荐,值得参考。
Generating Long-Term Structure in Songs and Stories
来自谷歌Magenta项目,利用Attention RNN创作乐曲,很有意思。
Attention模型由于其并行性,高效性及可解释性,逐渐会用在越来越多的有意思的应用场景中,值得期待。