Bert+CRF 层
Bert把中文文本进行了embedding,得到每个字的表征向量
dense操作得到了每个文本文本对应的未归一化的tag概率
CRF在选择每个词的tag的过程其实就是一个最优Tag路径的选择过程
CRF层能从训练数据中获得约束性的规则
比如开始都是以xxx-B,中间都是以xxx-I,结尾都是以xxx-E
比如在只有label1-I
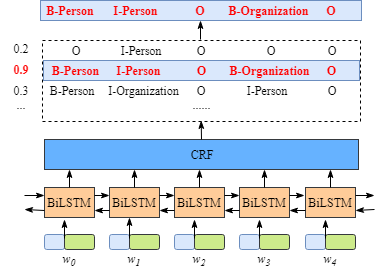
CRF层的输入是:每个词预测对应每个标签的分数 CRF层的输出是:每个可能的标注序列,并选择得分最高的序列作为最终结果; 如果没有CRF层的帮助,仅BiLSTM的话,模型只会选择每个词对应标签最大的概率作为输出,可能会出现I-Persion,I-location连接的错误情况,所以CRF的作用就是为模型提供一个标签约束关系: 这种约束为: 句子开头,以B-或O-开头,而不是以I-开头;
B-label1,I-label2,I-label3中,label必须是相同的实体标签;
有了这些约束,无效的预测序列数量就将显著减少;
CRF层怎么实现这些约束的呢?
在CRF层的损失函数中,我们有两种类型的分数。这两个分数是CRF层的关键概念。
2.1 发射概率Emission
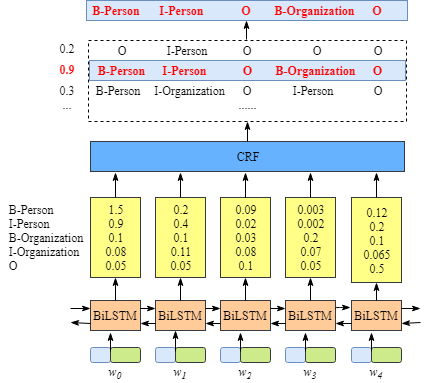
第一个是emission分数。这些emission分数来自BiLSTM层。例如上图所示,标记为B-Person的w0的分数为1.5。 所以,我们用表示发射概率,i表示第i个词的索引,y表示标签的索引。例如: 表示选择第0个词,第0个标签的发射概率;
2.2 转移概率Transition得分
我们用表示转移概率。例如,表示标签转移的分数,解释为B-person->I-persion的分数为0.9
为了使transition评分矩阵更健壮,我们将添加另外两个标签,START和END。START是指一个句子的开头,而不是第一个单词。END表示句子的结尾。
下图为为一个transition得分矩阵的例子,包括额外添加的START和END标签。
 我们可以发现transition矩阵已经学习了一些有用的约束。
例如START标签的转移,不可能是I标签开头;
B-perision后面转移到I-organization的概率很小;
你可能想问一个关于矩阵的问题。在哪里或如何得到transition矩阵?
实际上,该矩阵是BiLSTM-CRF模型的一个参数。
1)在训练模型之前,可以随机初始化矩阵中的所有transition分数。
那我们怎么训练这个转移概率呢;
我们可以发现transition矩阵已经学习了一些有用的约束。
例如START标签的转移,不可能是I标签开头;
B-perision后面转移到I-organization的概率很小;
你可能想问一个关于矩阵的问题。在哪里或如何得到transition矩阵?
实际上,该矩阵是BiLSTM-CRF模型的一个参数。
1)在训练模型之前,可以随机初始化矩阵中的所有transition分数。
那我们怎么训练这个转移概率呢;
2.3 损失函数
CRF损失函数由真实路径得分和所有可能路径的总分组成;
在所有可能路径中,目标是使真实路径的得分最高的;
如果第10条路径是真正的路径,则在所有可能路径中应占百分比最大;
总结
1、CRF层可以为最后预测的标签添加一些约束来保证预测的标签是合法的。在训练数据训练过程中,这些约束可以通过CRF层自动学习到的。约束可以是: I:句子中第一个词总是以标签“B-“ 或 “O”开始,而不是“I-”。 II:标签“B-label1 I-label2 I-label3 I-…”,label1, label2, label3应该属于同一类实体。例如,“B-Person I-Person” 是合法的序列, 但是“B-Person I-Organization” 是非法标签序列。 III:标签序列“O I-label” is 非法的.实体标签的首个标签应该是 “B-“ ,而非 “I-“, 换句话说,有效的标签序列应该是“O B-label”。 2、CRF中有转移特征,即它会考虑输出标签之间的顺序性,也会学习一些约束规则 3、CRF负责学习相邻实体标签之间的转移规则。