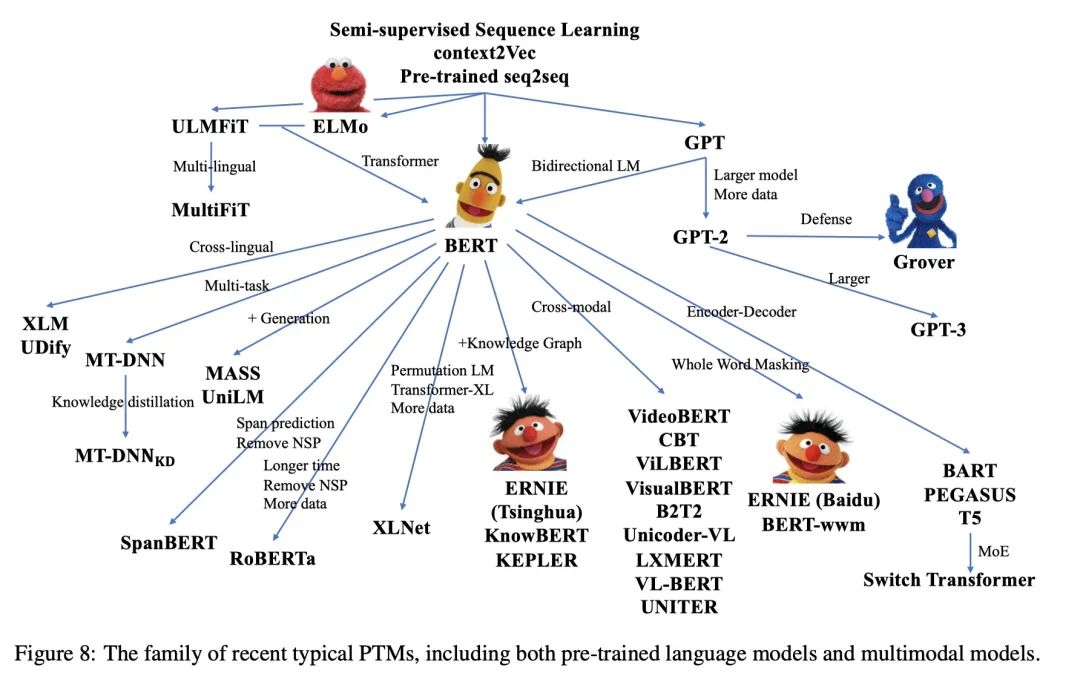
- 什么是BERT?
BERT全名 Bidirection Encoder Representations from Transformers,是谷歌于2018年发布的NLP领域的 预训练模型,一经发布就霸屏了NLP领域的相关新闻,味道是真香。果不其然,2019年出现了很多BERT相关的论文和模型,本文旨在对 BERT模型进行一个总结。
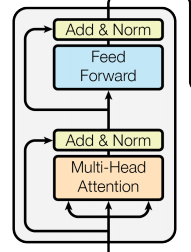
首先从名字就可以看出,BERT模型是使用双向Transformer模型的EncoderLayer进行特征提取(BERT模型中没有 Decoder部分)。Transformer模型作为目前NLP领域最牛的特征提取器其原理不需要多做介绍,其中的EncoderLayer-block结构如下图所示:
BERT的模型图如下所示:
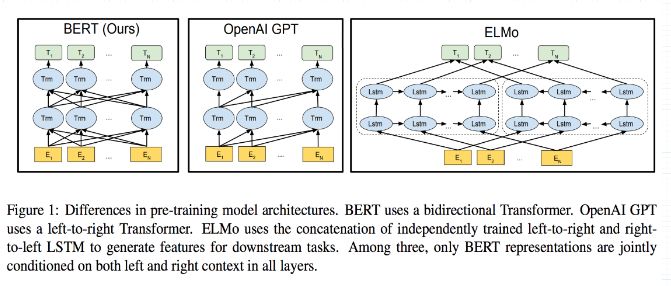
从图中可以看出BERT、GPT和ELMO三个模型的区别: BERT VS GPT : BERT 模型使用多层双向 Transformer 作为特征提取器,同时提取 上下文信息 , GPT 模型使用多层单向 Transformer 作为特征提取器,用于提取 上文信息 。相较于 GPT , BERT 多使用了 下文信息 ; BERT VS ELMO : BERT 模型使用多层双向 Transformer 作为特征提取器,同时提取 上下文信息 , ELMO 模型使用两对双层双向 LSTM 分别提取 上文信息 和 下文信息 ,然后将提取的信息进行拼接后使用。相较于 ELMO , BERT 使用了更强大的 Transformer 作为特征提取器,且 BERT 是同时提取上下文信息,相较于 ELMO 分别提取上文信息和下文信息,更加的“浑然天成”。
- 两个阶段 使用BERT模型解决NLP任务需要分为两个阶段: pre-train:用大量的无监督文本通过自监督训练的方式进行训练,把文本中包含的语言知识(包括:词法、语法、语义等特征)以参数的形式编码到 Transformer-encoderlayer 中。预训练模型学习到的是文本的通用知识,不依托于某一项NLP任务; fine-tune阶段:使用预训练的模型,在特定的任务中进行微调,得到用于解决该任务的定制模型;
- 两个任务 3.1 MLM 遮掩语言模型(Masked Language Modeling)。标准的语言模型(LM)是从左到右或者从右到左进行训练,但是BERT模型多层双向进行训练,因此BERT在训练时随机mask部分token,然后只预测那些被屏蔽的token。 MLM 学习的是单词与单词之间的关系。 但是MLM存在两个问题: pre-train 阶段与 fine-tune 阶段不匹配,因为在 fine-tune 期间不会有 [mask] token ; 每个batch只预测15%的token,因此需要训练更多的训练步骤才能收敛; 因此: 防止模型过度关注特定位置或masked token,模型随机遮掩15%的单词; mask token并不总被[mask]取代,在针对特定任务fine-tune时不需要进行[mask]标注; 具体做法: 随机选择15%的token; 选中的token并不总是被[mask] 取代,其中的80%的单词被[mask]取代; 其余10%的单词被其他随机单词取代; 剩余的10%的单词保持不变;3.2 NSP 下句预测(Next Sentence Prediction),该任务是一个二分类任务,预测第二句sentence是不是第一句sentence的下一句。 NSP 学习的是句子与句子之间的关系。 具体做法: 训练数据中的50%,第二句是真实的下句; 另外50%,第二句是语料库中的随机句子; 前50%的标签是 isNext ,后50%的标签是 notNext ;
- 模型输入
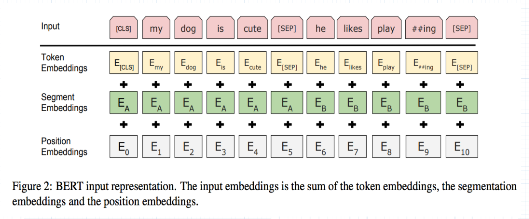
如上图所示,BERT模型有两个特殊的token:CLS(用于分类任务)、 SEP(用于断句),以及三个embedding:
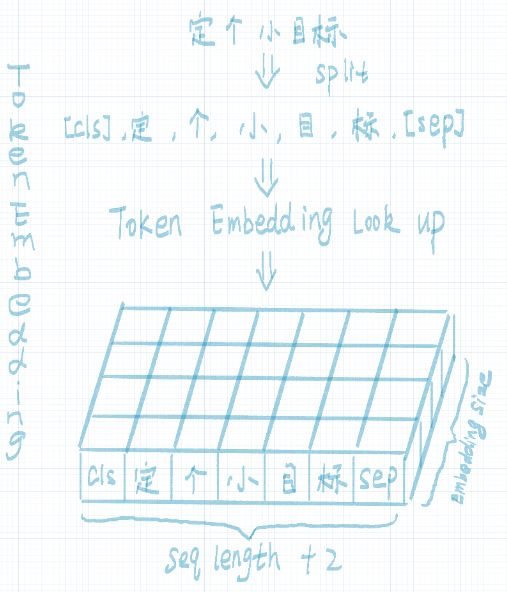
token embedding:输入的文本经过tokenization之后,将 CLS插入tokenization结果的开头, SEP 插入到tokenization结果的结尾。然后进行 token embedding look up 。shape为: [seq_length, embedding_dims]`。流程如下图所示:
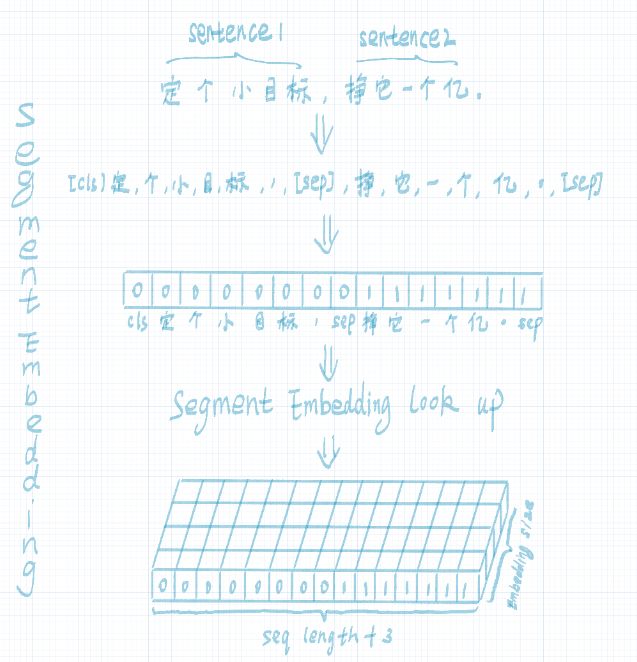
segment embedding:在 NSP 任务中,用于区分第一句和第二句。segment embedding中只有 0 和 1 两个值,第一句所有的token(包括 cls 和紧随第一句的 sep )的segment embedding的值为 0 ,第二句所有的token(包括紧随第二句的 sep )的segment embdding的值为 1 。shape为: [seq_length, embedding_dims] 。流程如下图所示:
position embedding:因 Transformer-encoderlayer 无法捕获文本的位置信息,而文本的位置信息又非常重要(“你欠我500万” 和 “我欠你500万”的感觉肯定不一样),因此需要额外把位置信息输入到模型中。 BERT 的位置信息是通过 sin函数 和 cos函数 算出来的,shape为: [seq_length, embedding_dims] 。该部分参数在训练时不参与更新。 备注:BERT的输入为:token_embedding + segment_embedding + position_embedding。
- BERT 为什么效果好? BERT模型用大量的无监督文本通过自监督训练的方式进行训练,把文本中包含的语言知识(包括:词法、语法、语义等特征)以参数的形式编码到Transformer-encoderlayer中。有研究表明: 低层的 Transformers-EncoderLayer :主要学习了编码表层的特征; 中层的 Transformers-EncoderLayer :主要学习了编码句法的特征; 高层的 Transformers-EncoderLayer :主要学习了编码语义的特征;