前言
《动手学习深度学习》是李沐老师(AWS 资深首席科学家,美国卡内基梅隆大学计算机系博士)主讲的一系列深度学习视频。本笔记记录了该课程的重点知识。
课程简介
通常我们提到深度学习,常常会忘记深度学习只是机器学习的一小部分,而认为它是独立于机器学习的单独模块。这是因为机器学习作为一门历史更悠久的学科,在深度学习没有问世之前,在现实世界的应用范围很窄。在语音识别、计算机视觉、自然语言处理等领域,由于需要大量的领域知识并且现实情况异常复杂,机器学习往往只是解决这些领域问题方案中的一小部分。但是就在过去的几年里,深度学习的问世和应用给世界带来了惊喜,推动了计算机视觉、自然语言处理、自动语音识别、强


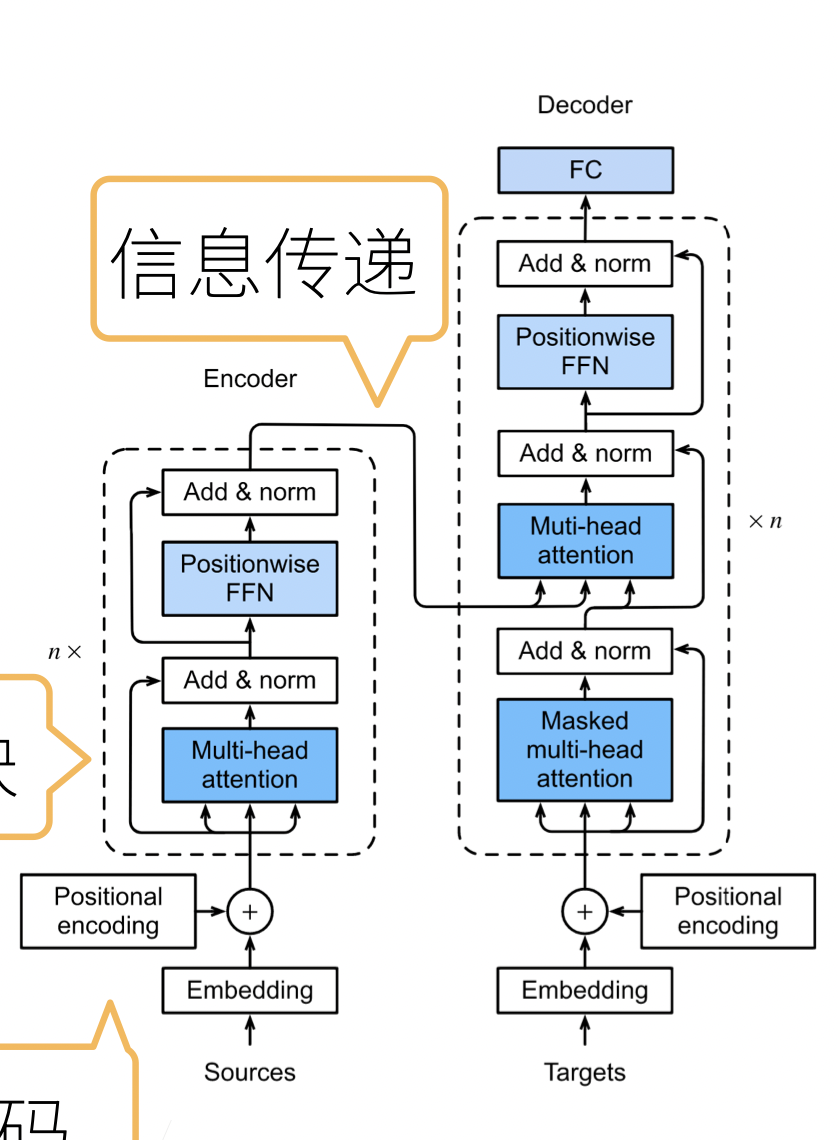

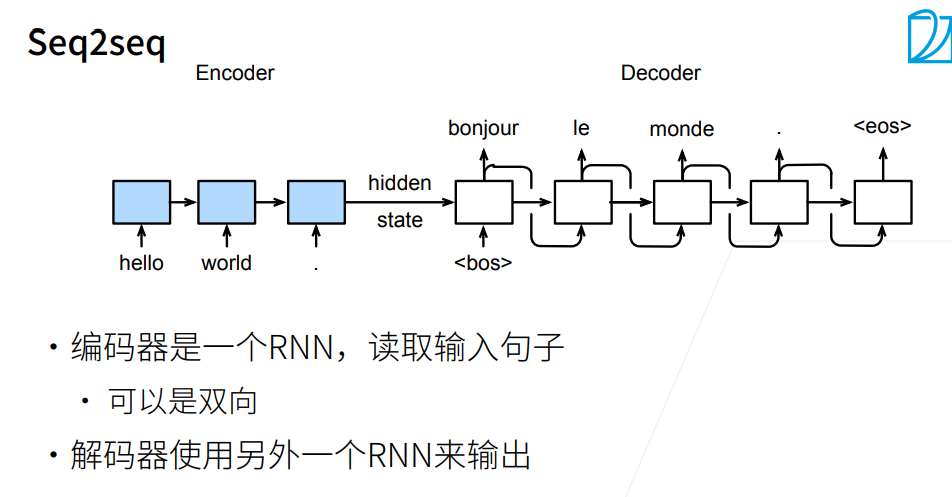
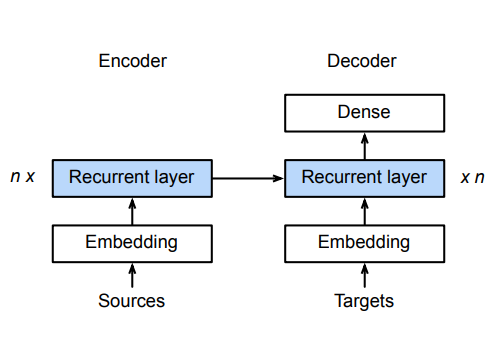
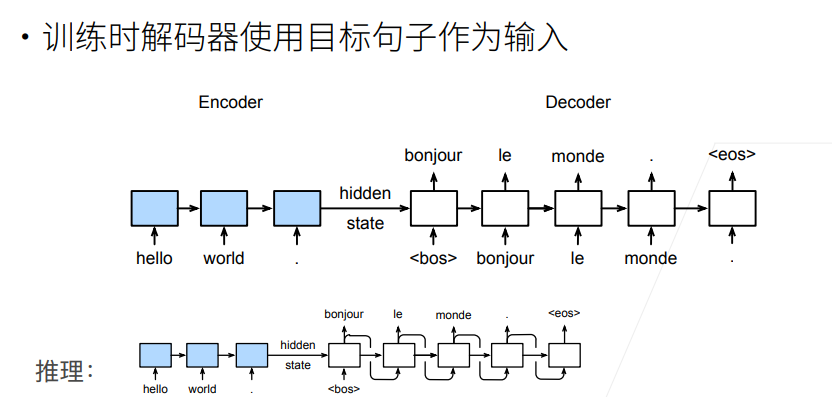
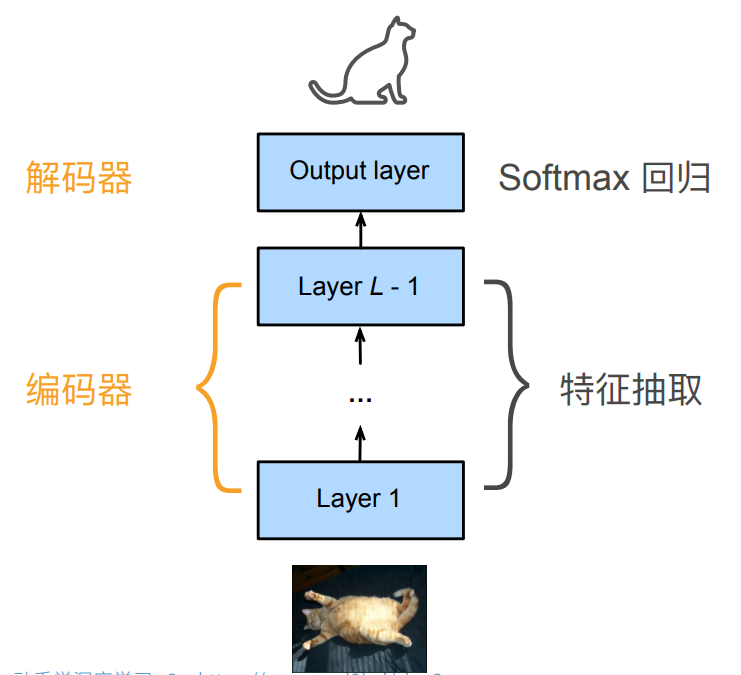 整个CNN实际上可以看作一个编码器,解码器两部分。
整个CNN实际上可以看作一个编码器,解码器两部分。
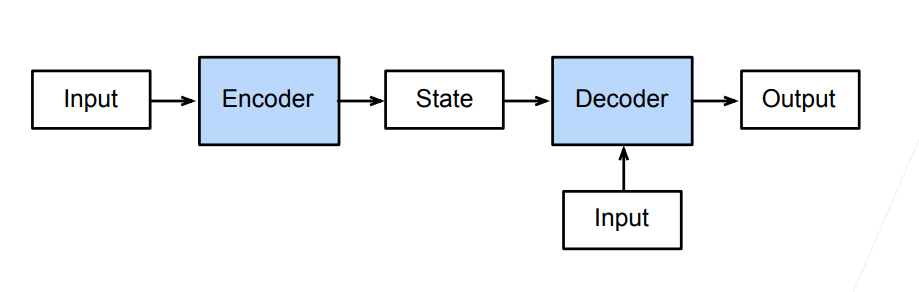
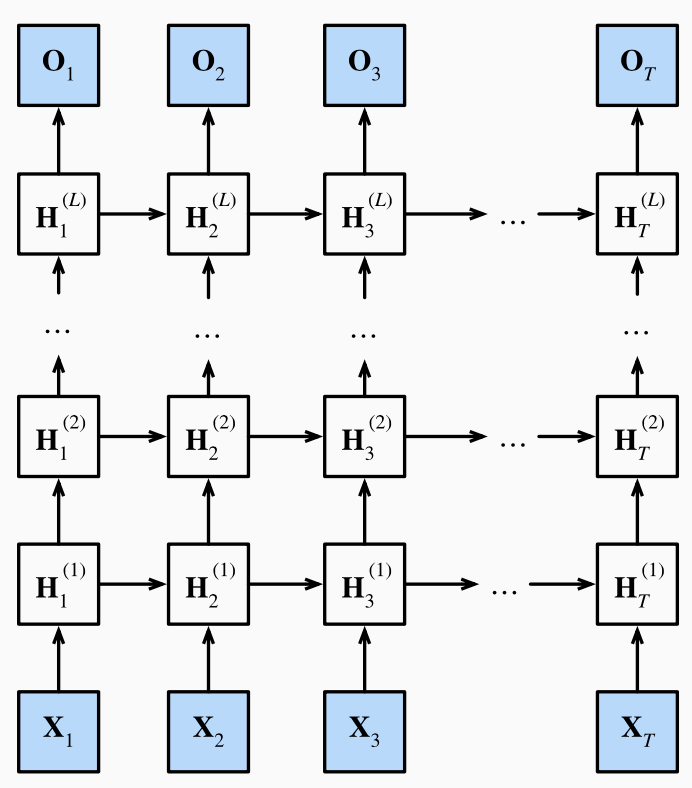 (课程视频中的图片有错误,最后输出层后一时间步是不受前一步影响的,即没有箭头)
(课程视频中的图片有错误,最后输出层后一时间步是不受前一步影响的,即没有箭头)