引言
语音合成,又称文语转换(Text To Speech, TTS),是一种可以将任意输入文本转换成相应语音的技术。 Tacotron2 论文地址:Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
基于传统方法的语音合成
传统的语音合成系统通常包括前端和后端两个模块。前端模块主要是对输入文本进行分析,提取后端模块所需要的语言学信息,对于中文合成系统而言,前端模块一般包含文本正则化、分词、词性预测、多音字消歧、韵律预测等子模块。后端模块根据前端分析结果,通过一定的方法生成语音波形,后端系统一般分为基于统计参数建模的语音合成(或称参数合成)以及基于单元挑选和波形拼接的语音合成(或称拼接合成)。
基于深度学习的语音合成
WaveNet
WaveNet并非一个端到端的TTS系统,依赖于其他模块对输入预处理,提供特征。详见下文“声码器”部分,论文地址:WaveNet: A generative model for raw audio 仿照PixelRNN 图像生成方式,WaveNet依据之前采样点来生成下一采样点。WaveNet是一种典型的自回归生成模型,所谓自回归生成模型,即是利用前面若干时刻变量的线性组合来描述以后某时刻变量的线性回归模型,参见第四篇 自回归模型(AR Model)。WaveNet生成下一个采样点的结构为CNN结构。 WaveNet缺陷:1)每次预测一个采样点,速度慢;2)WaveNet并非完整的TTS方案,依赖其余模块提供高层特征,前端分析出错,直接影响合成效果;3)用于TTS时,初始采样点的选择很重要
DeepVoice
将传统参数合成的TTS系统分拆成多个子模块,每个子模块用一个神经网络模型代替。论文地址:Deep voice: Real-time neural text-to-speech DeepVoice将语音合成分成5部分进行,分别为:文本转音素(又称语素转音素, G2P)、音频切分、音素时长预测、基频预测、声学模型。
文本转音素
DeepVoice直接输入文本即可,但是由于不同语言存在“同字不同音”的现象,因此需要将文本转化为注音字符。对于中文而言,就是将汉字转化为拼音。
音频切分
获得每个音素在对应音频中的起点和终点。使用Deep Speech 2: End-to-End Speech Recognition in English and Mandarin的对齐方法,这些对齐信息用于训练后面的“音素时长预测”模型。
音素时长预测和基频预测
该模型为多任务模型,输入带有重音标注的音素序列,输出为音素时长、是否发音的概率和基频
声学模型
即后文的“声码器”(Vocoder)。用于将前面得到的高层特征转换为声音波形。DeepVoice的声学模型即是在前文的WaveNet基础上改进的。改进的主要方向是:改变网络层数、残差通道数、矩阵乘代替上采样卷积、CPU优化、GPU优化等。 DeepVoice优势在于:提供了完整的TTS解决方案,不像WaveNet需要依赖其它模块提供特征,使用的人工特征也减少了;合成速度快,实时性好 DeepVoice缺陷:误差累积,5个子模块的误差会累积,一个模块出错,整个合成失败,开发和调试难度大;虽然减少使用了人工特征,但在这个完整的解决方案中,仍然需要使用音素标记、重音标记等特征;直接使用文本输入,不能很好解决多音字问题。
Tacotron
真正意义上的端到端语音合成系统,输入文本(或注音字符),输出语音。论文地址:Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model。
结构为:Encoder -> Attention -> Decoder -> Post-processing -> Griffin-Lim转为声音波形。后文“Tacotron”部分详述了这个方法。
Tacotron优势在于:减少特征工程,只需输入注音字符(或文本),即可输出声音波形,所有特征模型自行学习;方便各种条件的添加,如语种、音色、情感等;避免多模块误差累积
Tacotron缺陷:模型除错难,人为干预能力差,对于部分文本发音出错,很难人为纠正;端到端不彻底,Tacotron实际输出梅尔频谱(Mel-Spectrum),之后再利用Griffin-Lim这样的声码器将其转化为最终的语音波形,而Griffin-Lim造成了音质瓶颈。
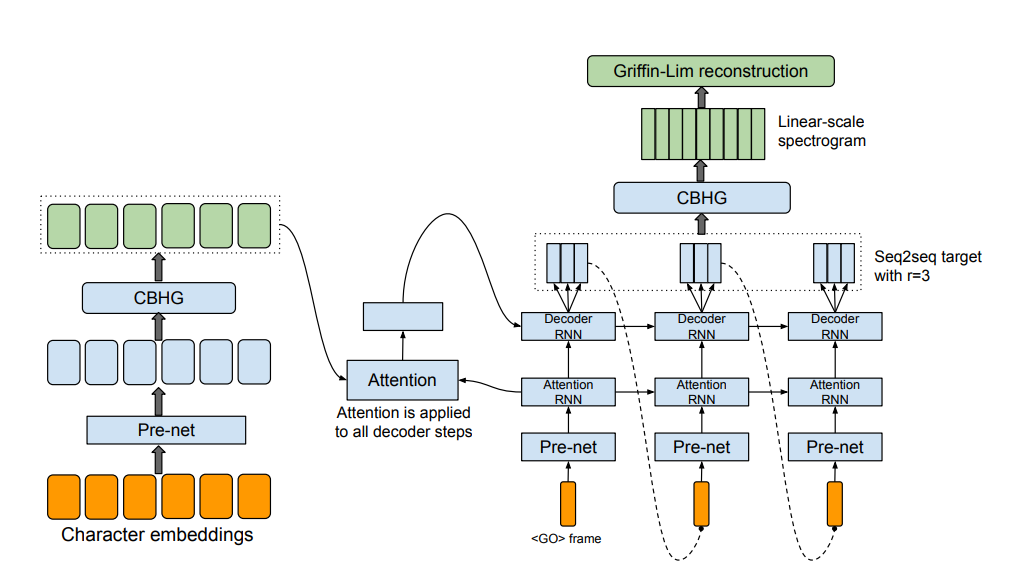
整个特征预测网络是一个带有注意力机制(attention)的seq2seq网络。
Tacotron2
Tacotron2使用了一个和Wavenet十分相似的模型来代替Griffin-Lim算法,同时也对Tacotron模型的一些细节也做了更改,最终生成了十分接近人类声音的波形。
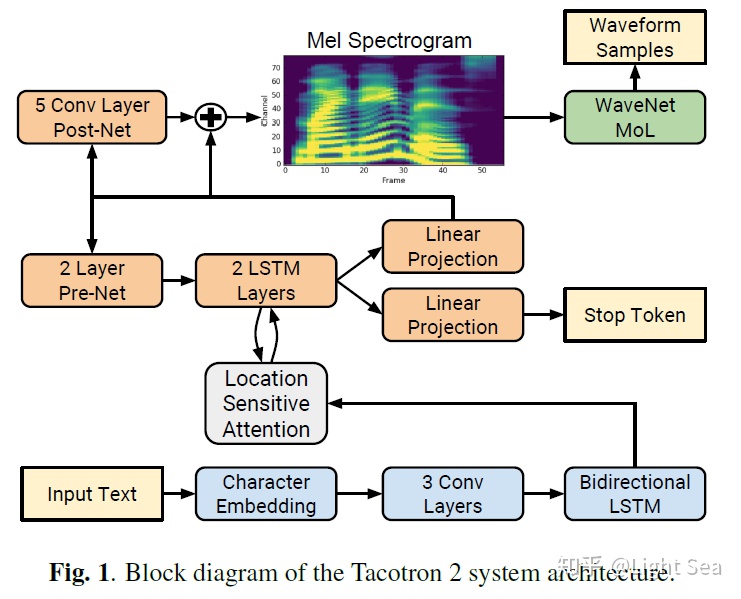
模型的架构如下图所示:
 preview
和Tacotron一样,pre-net的功能是作为bottleneck layer来增加泛化能力和加速收敛。
除了Wavenet,Tacotron2和Tacotron的主要不同在于:
不使用CBHG,而是使用普通的LSTM和Convolution layer
decoder每一步只生成一个frame
增加post-net,即一个5层CNN来精调mel-spectrogram
preview
和Tacotron一样,pre-net的功能是作为bottleneck layer来增加泛化能力和加速收敛。
除了Wavenet,Tacotron2和Tacotron的主要不同在于:
不使用CBHG,而是使用普通的LSTM和Convolution layer
decoder每一步只生成一个frame
增加post-net,即一个5层CNN来精调mel-spectrogram