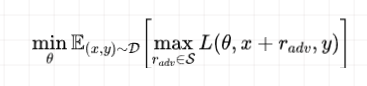Deepseek-LLM (V1-V3)系列
V1模型重点在于保障效果的前提下,探索低成本算法,在低成本情况下做Scaling Laws实验,打牢基础。延用LLAMA 2 稠密(Dense)模型的架构,使用2万亿Token的中英数据来做超参数和模型大小/数据配比的Scaling Laws实验,后训练阶段使用SFT和DPO算法,在多个维度超越LLaMa2 70B。
V2模型的模型参数比V1模型翻了3.5倍,训练数据量比V1多了4倍,基于论文H800用时推测预训练算力成本只增加一倍。训练效率提升主要是依靠MoE (Mixture-of-Experts)架构,为什么要从Dense架构变为MoE架构,