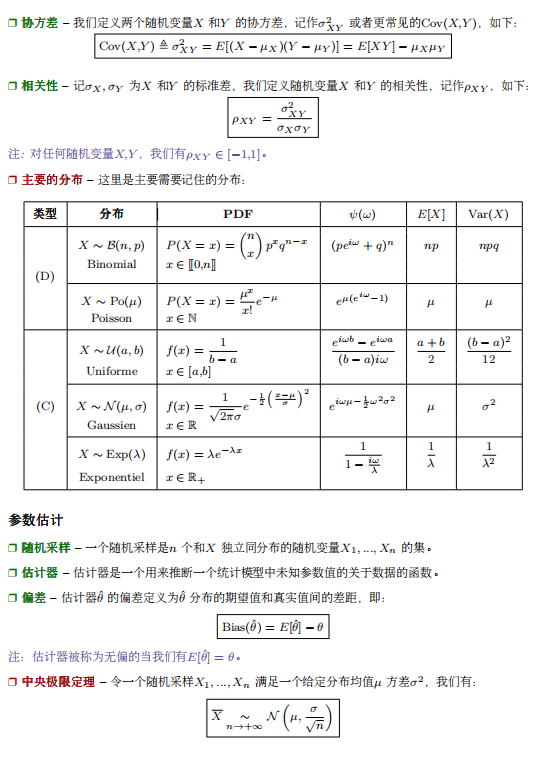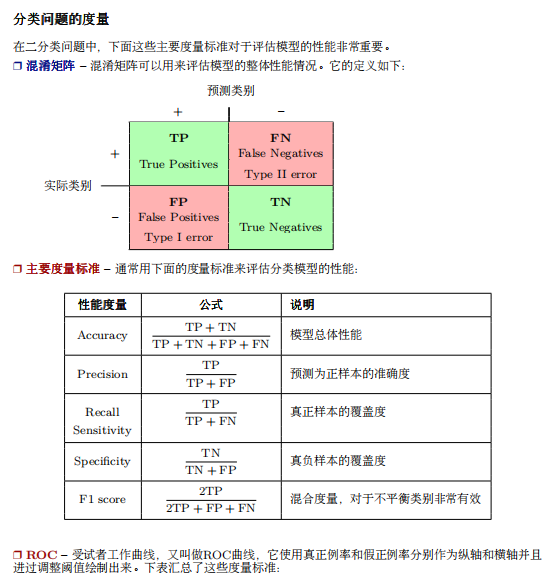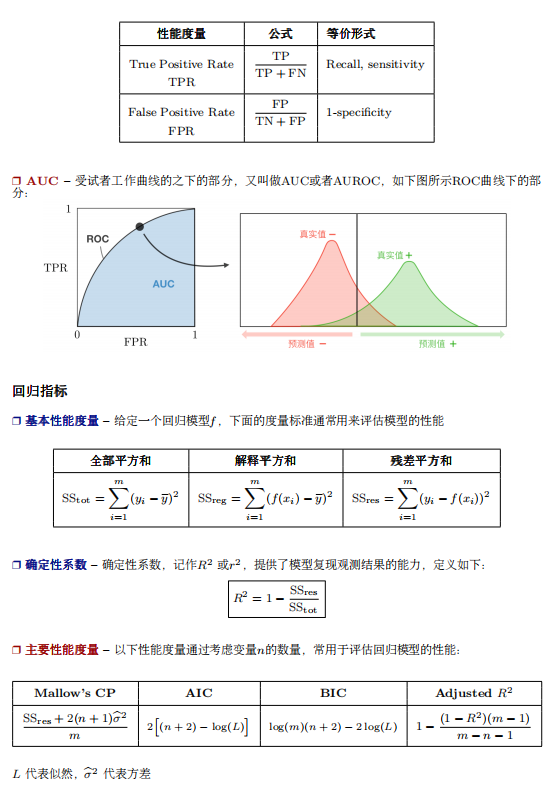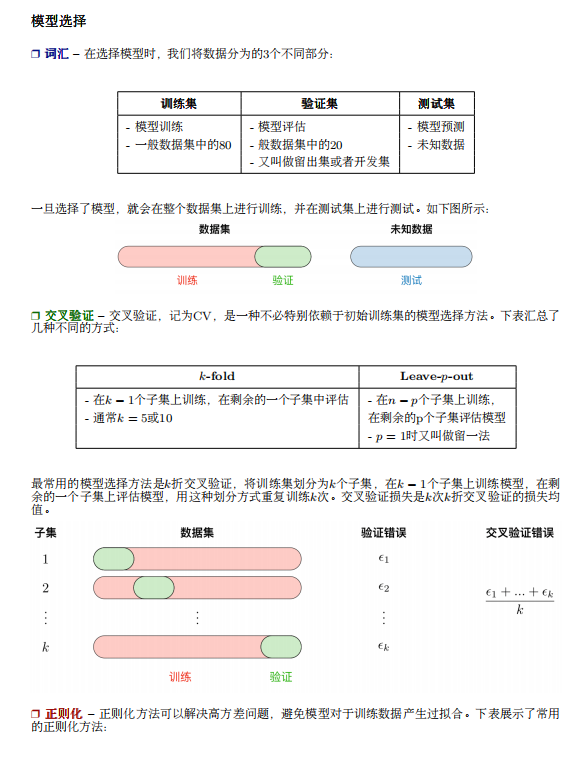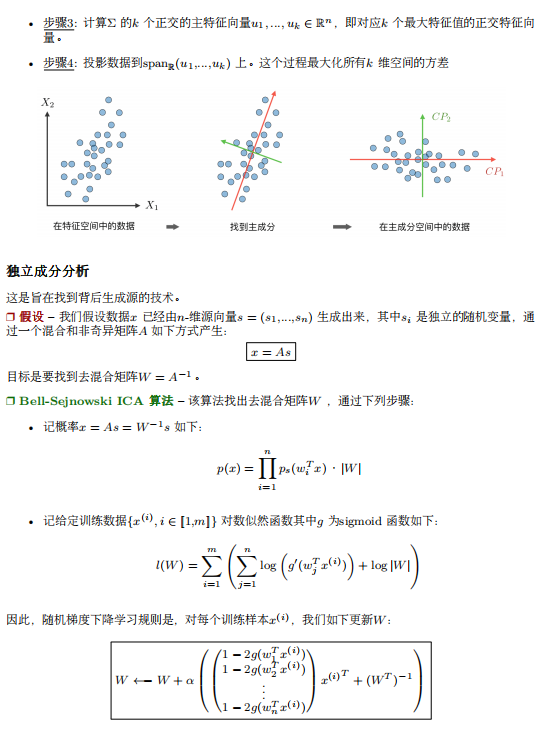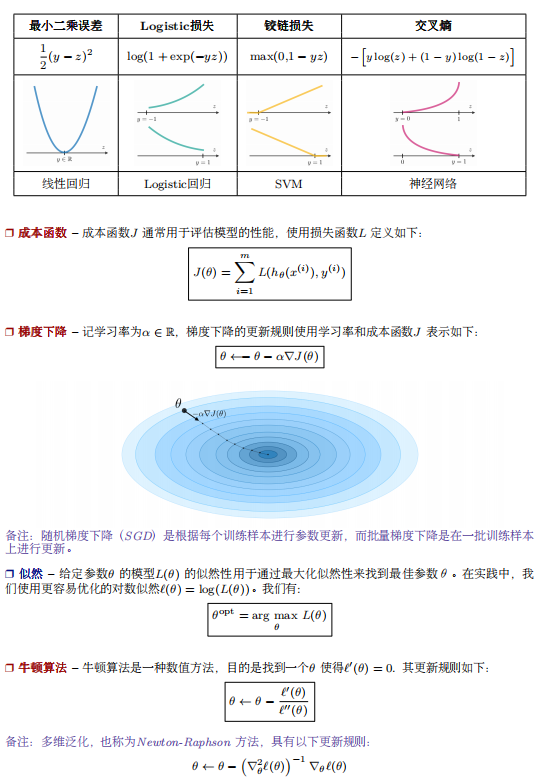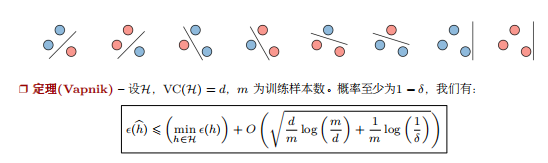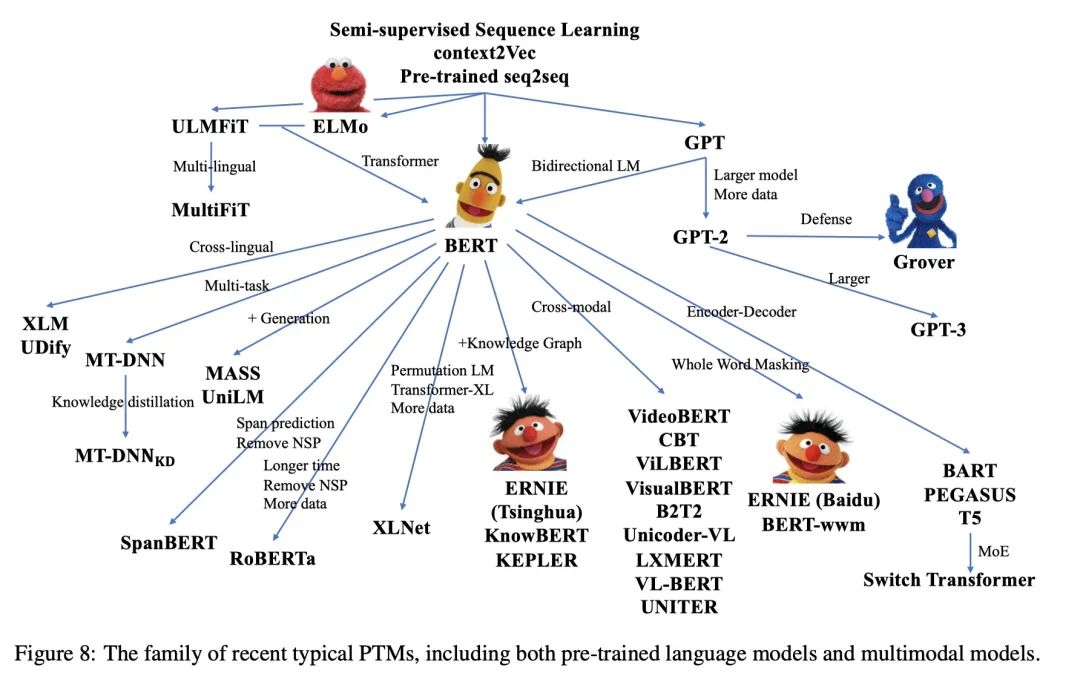
- 什么是BERT? BERT全名 Bidirection Encoder Representations from Transformers,是谷歌于2018年发布的NLP领域的 预训练模型,一经发布就霸屏了NLP领域的相关新闻,味道是真香。果不其然,2019年出现了很多BERT相关的论文和模型,本文旨在对 BERT模型进行一个总结。 首先从名字就可以看出,BERT模型是使用双向Transformer模型的EncoderLayer进行特征提取(BERT模型中没有 Decoder部分)。Transformer模型作为目前NLP领域最牛的特征提取器其原理不需要多做介绍,其中的EncoderLay