Deepseek-LLM (V1-V3)系列
V1模型重点在于保障效果的前提下,探索低成本算法,在低成本情况下做Scaling Laws实验,打牢基础。延用LLAMA 2 稠密(Dense)模型的架构,使用2万亿Token的中英数据来做超参数和模型大小/数据配比的Scaling Laws实验,后训练阶段使用SFT和DPO算法,在多个维度超越LLaMa2 70B。
V2模型的模型参数比V1模型翻了3.5倍,训练数据量比V1多了4倍,基于论文H800用时推测预训练算力成本只增加一倍。训练效率提升主要是依靠MoE (Mixture-of-Experts)架构,为什么要从Dense架构变为MoE架构,主要是Dense架构计算效率低,所有的输入都要激活所有参数参与计算,会导致大量冗余和不必要的算力浪费。MoE架构的稀疏激活和动态路由特点就可以很好的解决这些问题。同时Deepseek打响了API的价格战,当时号称GPT4的性能但API价格只有GPT4的百分之一。推理成本低的功劳是在与他们提出的MLA (Multi-Head Latent Attention)大大节约了KVcache显存的占用,MLA会在文章后面详细讲解。
V3模型参数量相较于V2模型多了三倍,训练数据量比V2模型增加接近一倍,但是V3模型训练成本控制在557.6万美元,重点是MoE、MLA、FP8混合精度训练在起作用。之后一个月推出了R1,在V3作为底座的基础上通过多阶段SFT和强化学习达到o1水平的模型,至此,登上王座成功破圈。
Deepseek R1系列
1. R1关键贡献
DeepSeek-R1-Zero模型是一个纯粹通过强化学习来增强的强推理模型,摆脱了传统使用SFT训练所需的海量标注数据,同时使用基于规则的reward计算方式,解决了传统强化学习中引入基于模型的reward计算方式带来的reward hacking问题,使强化学习过程更加稳定
GRPO提供了一种新的思路,相比PPO,GRPO摒弃了价值模型,转而从组得分中估计基线,显著降低了训练资源消耗。
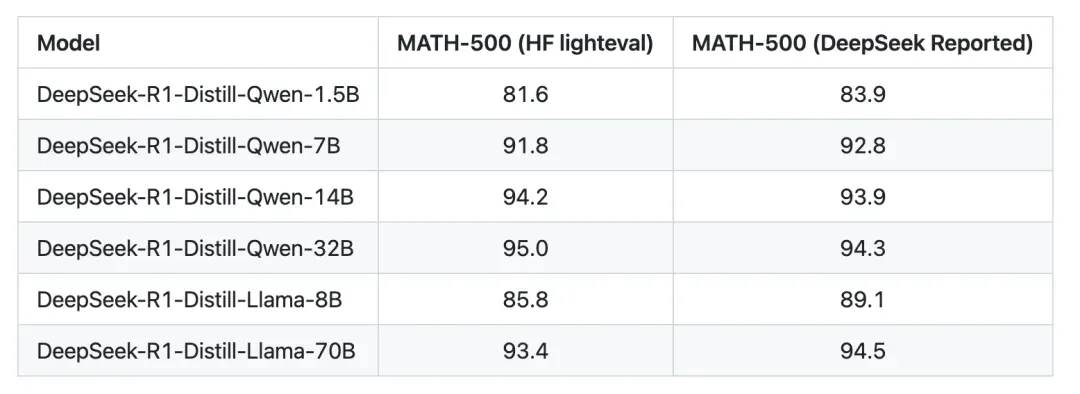
(低成本快速复制推理能力)探索了如何将大模型(如DeepSeek-R1)学到的推理模式蒸馏到小模型中。这一蒸馏方法使得小模型在推理任务上表现出色,超越了一些最先进的模型。论文中提到用了800K的生成推理数据训练过一些小规模的模型后(1.5B、7B、14B、32B、70B)测试表现良好
R1存在的问题
论文中提到,在R1的训练结果中也出现了很多问题,这对我们后续的复现和使用都是一个参考:
通用能力(General Capability):
目前,DeepSeek-R1在函数调用、多轮对话、复杂角色扮演和JSON输出等任务上不如DeepSeek-V3。未来计划探索如何利用长链式思维(CoT)提升这些任务的表现。
语言混合(Language Mixing):
DeepSeek-R1目前针对中文和英文进行了优化,但在处理其他语言时可能出现语言混合问题。未来计划解决这一问题。
提示工程(Prompting Engineering):
DeepSeek-R1对提示敏感,少样本提示(few-shot prompting)会降低其性能。建议用户在零样本(zero-shot)设置下直接描述问题并指定输出格式,以获得最佳结果。
软件工程任务(Software Engineering Tasks):
由于评估时间较长,影响RL过程的效率,大规模RL尚未广泛应用于软件工程任务。未来版本将通过拒绝采样(rejection sampling)或异步评估来提高效率。
复现R1项目分析
R1-Zero复现项目:Logic-RL
开源项目地址:https://github.com/Unakar/Logic-RL
训练数据
只有2K不到的训练数据集,完全由程序合成,确保对基座模型是OOD数据(这些数据在模型训练时从未见过)。 其中逻辑问题类似老实人和骗子的益智题,老实人总说真话,骗子总说假话,下面N个人,各有各的表述,请判断谁是骗子。我们以此为例讲解实验细节。 一些训练用的数据格式示例:

训练过程
训练过程分为三个阶段
预热阶段,此部分主要是课程学习与格式遵循,用少量简单题目引导模型学习
高温采样与大量rollout,此阶段调高温度进行大量采样,此阶段训练持续最长,也最不稳定,是各种能力涌现的时段。
退火,温度学习率学习率递减,此阶段模型的输出已经趋于稳定,有verify,有反思,有回溯,有格式。
训练结果
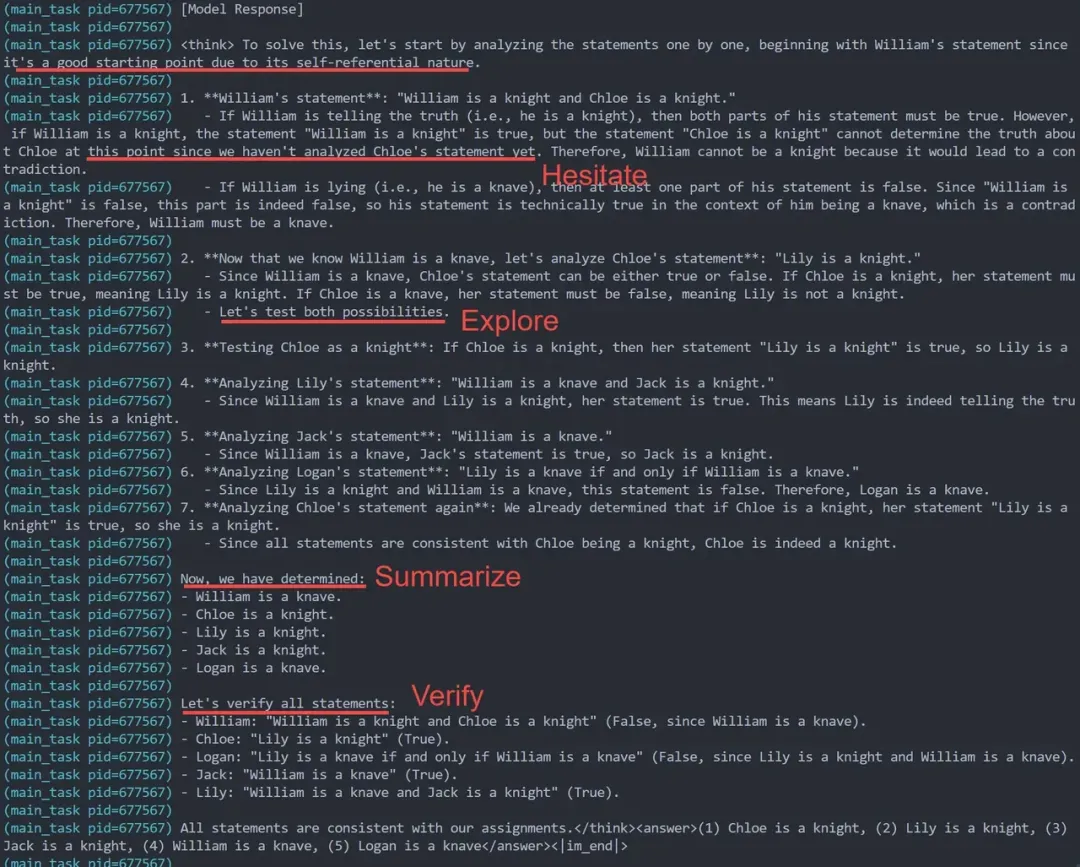
复现实验中观察到了论文中提到的 自我进化过程(Self-evolution Process of DeepSeek-R1-Zero),包括模型思考时间的增加,自发行为的出现,反思(Reflection),验证(Verify),“顿悟时刻”(Aha Moment of DeepSeek-R1-Zero)
原始基座模型在测试集上只会基础的step by step逻辑。
无 Long CoT冷启动蒸馏,三阶段Rule Based RL后,模型学会了
- 迟疑 (标记当前不确定的step等后续验证),
- 多路径探索 (Les't test both possibilities),
- 回溯之前的分析 (Analyze .. statement again),
- 阶段性总结 (Let's summarize, Now we have determined),
- Answer前习惯于最后一次验证答案(Let's verify all statements),
- Think时偶尔切换多语言作答 (训练数据纯英文的情况下,思考部分是中文,最后answer又切回英文)如下是训练过程中的部分日志,证明模型确实可以从强化学习中自我进化出各种能力。
蒸馏实验复现:Open-R1
蒸馏实验分析来自于开源项目
https://github.com/huggingface/open-r1
step1:通过DeepSeek-R1蒸馏的数据训练
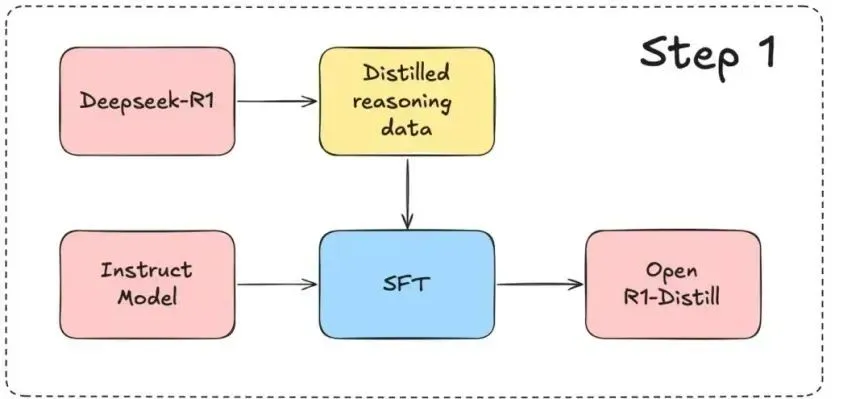
使用 DeepSeek-R1 的 蒸馏数据创建了 Bespoke-Stratos-17k——一个包含问题、推理轨迹和答案的推理数据集。制作好的数据集参见:
https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k。
这里面的关键是推理轨迹,通过R1得到,但是是英文的数据集。
该数据集包含:
5,000 条来自 APPs 和 TACO 的编程数据;
10,000 条来自 NuminaMATH 数据集的 AIME、MATH 和 Olympiads 子集的数学数据;
1,000 条来自 STILL-2 的科学和谜题数据。
生成过程:
高效数据生成:通过 Bespoke Curator(用于生成和管理高质量合成数据的项目) 和 DeepSeek-R1,仅用 1.5 小时生成高质量推理数据集,成本控制在 800 美元。
改进拒绝采样:引入 Ray 集群加速代码验证,作者后面计划直接集成代码执行验证器。
优化推理轨迹:DeepSeek-R1 的推理轨迹质量高,无需额外格式化步骤,简化了流程。
提升数学解题精度:通过 gpt-4o-mini,过滤错误的数学解决方案,显著提高了正确数学解决方案的保留率(从 25% 提升至 73%)。
部分训练数据可视化结果:

项目中使用qwen各个规模的模型作为基座进行蒸馏实验对比,指标均有明显提升。