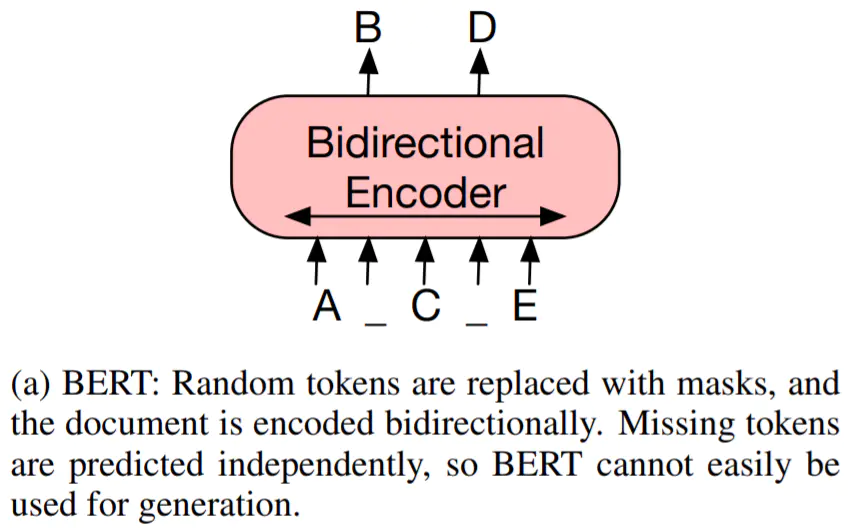
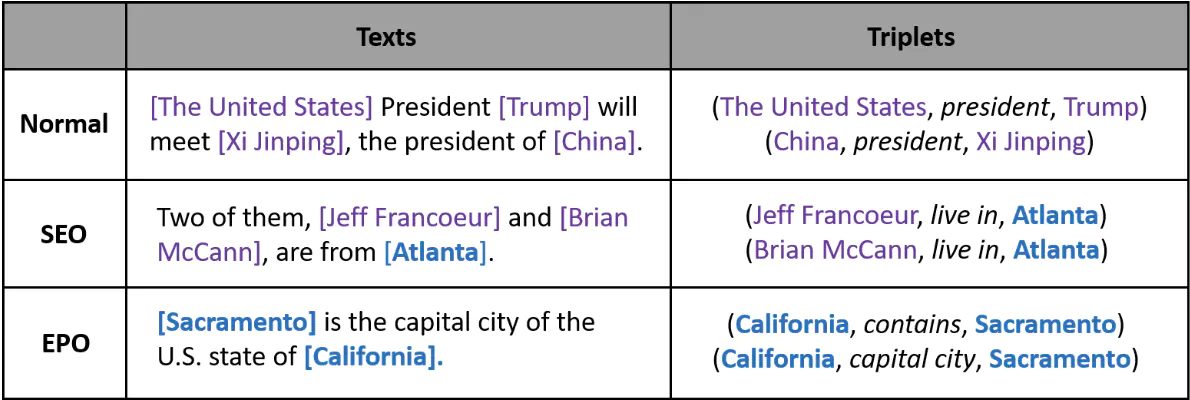
这篇40多页的综述出自哈工大车万翔老师的团队,一共总结了15种NLP可以用到的数据增强方法、优缺点,还有一些使用技巧,十分良心。下面就速读一下,如果要使用的话还是建议参考原文以及其他文献的应用细节。 论文:Data Augmentation Approaches in Natural Language Processing: A Survey 地址:https://arxiv.org/abs/2110.01852
数据增强方法
数据增强(Data Augmentation,简称DA),是指根据现有数据,合成新数据的一类方法。毕竟数据才是真正的效果天花板,有了更多数据后可以提升效果、增强模型泛化