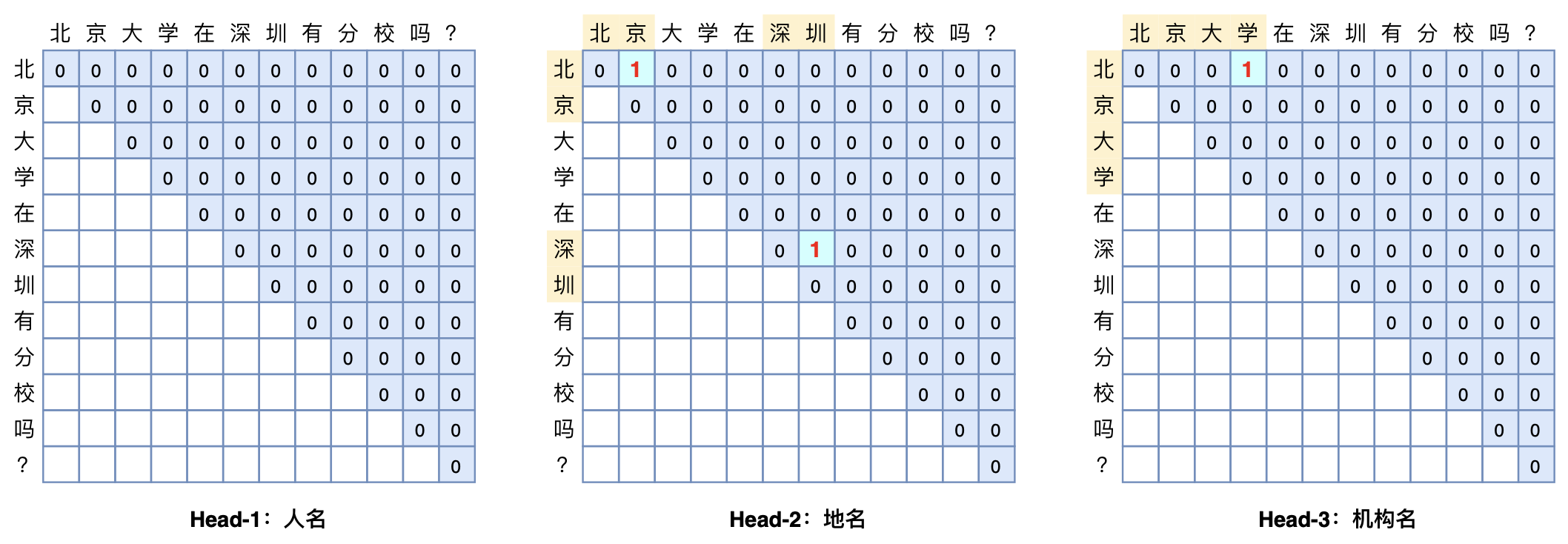
BERT预训练
1.目录:
2.BERT:
2.1 NLP里的迁移学习
使用预训练好的模型来抽取词,句子的特征
- 例如word2vec或语言模型
不更新预训练好的
分类目录归档:深度学习
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是O(1)! 简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
 GlobalPoniter多头识别嵌套实体示意图
GlobalPoniter多头识别嵌套实体示意图
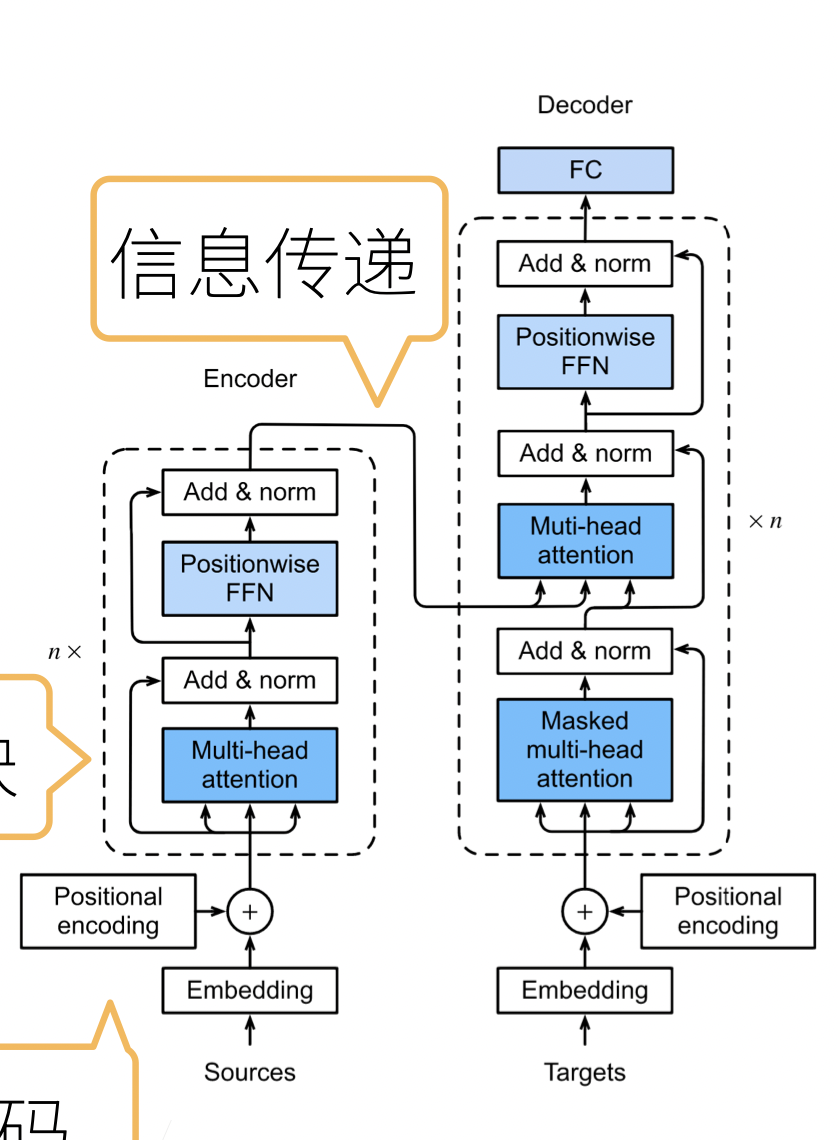
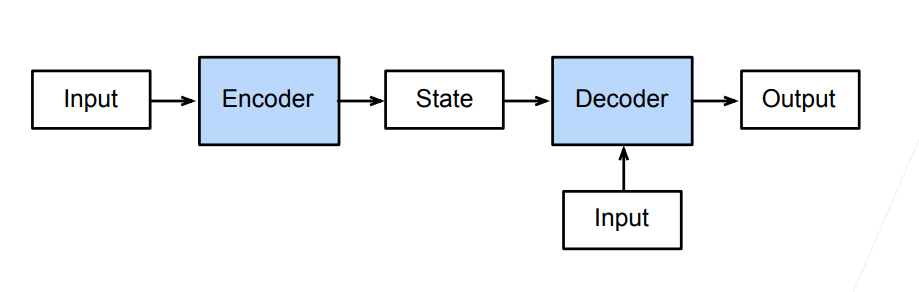
基于encoder-decoder架构来处理序列对
对同一key,value,query,希望抽取不同的信息
多头注意力使用h个独立的注意力池化

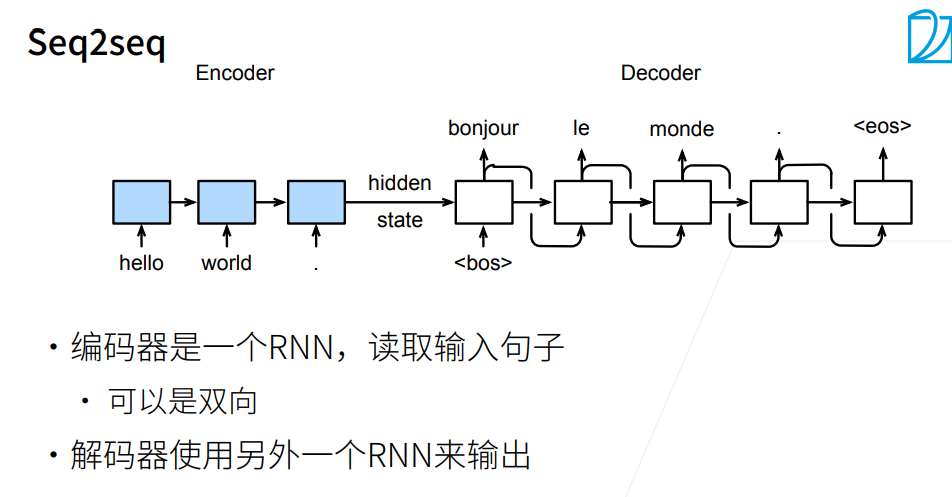
在序列生成问题中,常用的方法是一个个词元地进行生成,但是先前步生成的词元会影响之后词元的概率分布,为此,我们需要使用搜索算法来得到一个较好的序列
贪心搜索即每个时间步都选择具有最高条件概率的词元。 $$ y{t'} = \operatorname*{argmax}{y \in \mathcal{Y}} P(y \mid y1, \ldots, y{t'-1}, \mathbf{c}) $$ 我们的目标是找到一个最有序列,他的联合概率,也就是每步之间的条件概率的乘积,最大。 $$ \prod{t'=1}^{T'} P(y{t'} \mid y1, \ldots, y{t'-1}
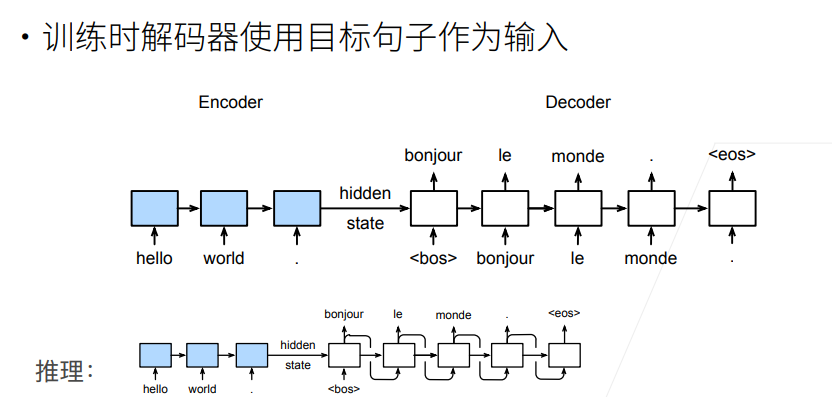
序列到序列模型由编码器-解码器构成。
编码器RNN可以是双向,由于输入的句子是完整地,可以正着看,也可以反着看;而解码器只能是单向,由于预测时,只能正着去预测。
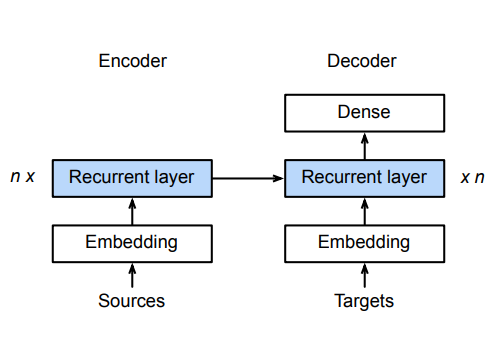
编码器的RNN没有连接输出层
编码器的最后时间步的隐状态用作解码器的初始隐状态(图中箭头的传递)
考虑一个CNN模型:
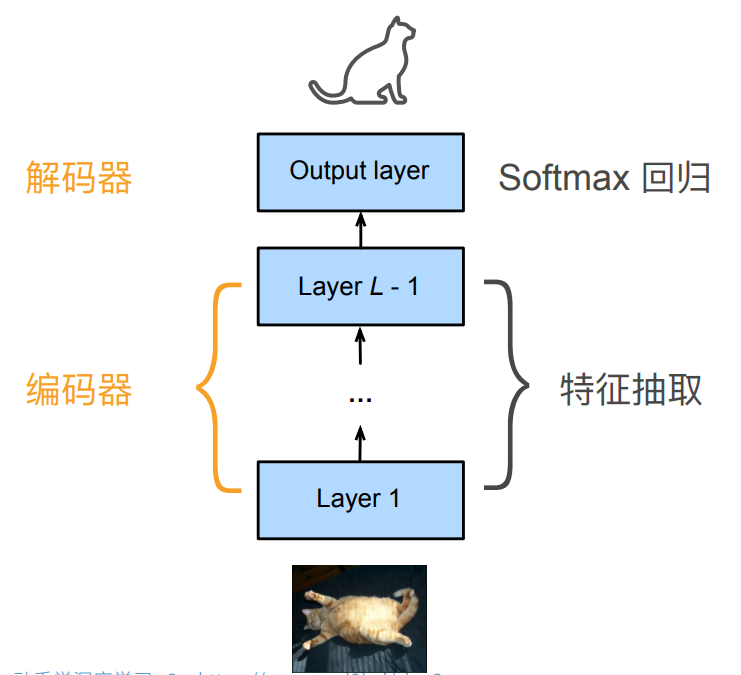 整个CNN实际上可以看作一个编码器,解码器两部分。
整个CNN实际上可以看作一个编码器,解码器两部分。
对于RNN而言,同样有着类似的划分

指一个模型被分为两块:
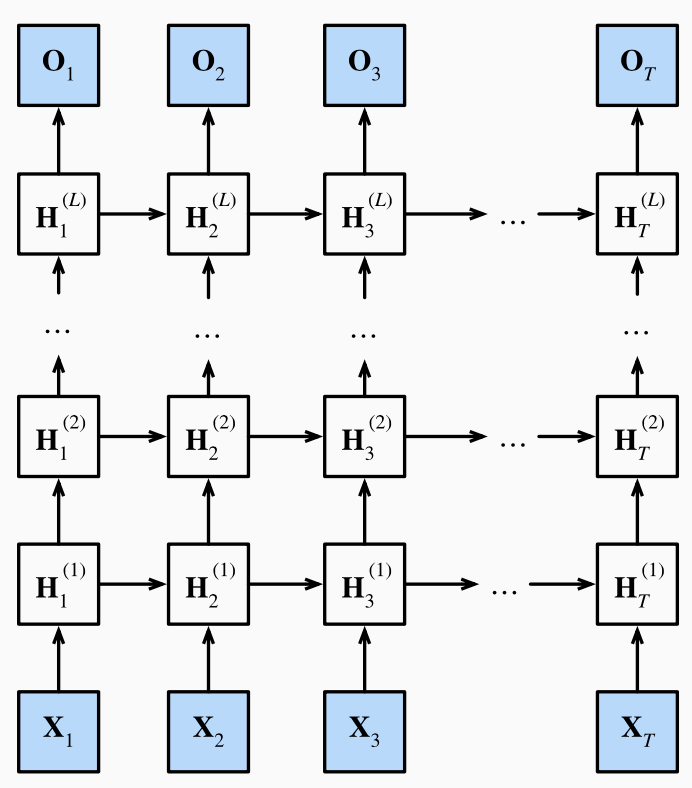
之前讲的RNN都只有一个隐藏层(序列变长不算是深度),而一个隐藏层的RNN一旦做的很宽就容易出现过拟合。因此我们考虑将网络做的更深而非更宽,每层都只做一点非线性,靠层数叠加得到更加非线性的模型。
浅RNN:输入-隐层-输出
深RNN:输入-隐层-隐层-...-输出
 (课程视频中的图片有错误,最后输出层后一时间步是不受前一步影响的,即没有箭头)
(课程视频中的图片有错误,最后输出层后一时间步是不受前一步影响的,即没有箭头)
可以说,长短期记忆网络的设计灵感来自于计算机的逻辑门。 长短期记忆网络引入了记忆元(memory cell),或简称为单元(cell)。 有些文献认为记忆元是隐状态的一种特殊类型, 它们与隐状态具有相同的形状,其设计目的是用于记录附加的信息。 为了控制记忆元,我们需要许多门。 其中一个门用来从单元中输出条目,我们将其称为输出门(output gate)。 另外一个门用来决定何时将数据读入单元,我们将其称为输入门(input gate)。 我们还需要一种机制来

比如上图中的序列,若干个猫中出现了一个鼠,那么我们应该重点关注这个鼠,而中间重复出现的猫则减少关注。文本序列同理,通常长文本我们需要关注的是几个关键词,关键句。
更新门Zt,重置门Rt的公式大体相同,唯一不同的是学习到的参数。
需要注意的是,计算门的方式和原来RNN的实现中计算新的隐状态相似,只是激活函数改成了sig