对抗训练本质是为了提高模型的鲁棒性,一般情况下在传统训练的基础上,添加了对抗训练是可以进一步提升效果的,在比赛打榜、调参时是非常重要的一个trick。对抗训练在CV领域内非常常用,那么在NLP领域如何使用呢?本文简单总结几种常用的对抗训练方法。
对抗训练旨在对原始输入样本x上施加扰动 r,得到对抗样本后用其进行训练:
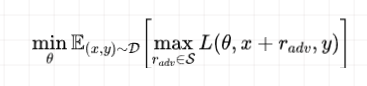
公式理解: 最大化扰动:挑选一个能使得模型产生更大损失(梯度较大)的扰动量,作为攻击; 最小化损失:根据最大的扰动量,添加到输入样本后,朝着最小化含有扰动的损失(梯度下降)方向更新参数;
这个被构造出来的“对抗样本”并不能具体对应到某个单词,因此,反过来在推理阶段是没有办法通过
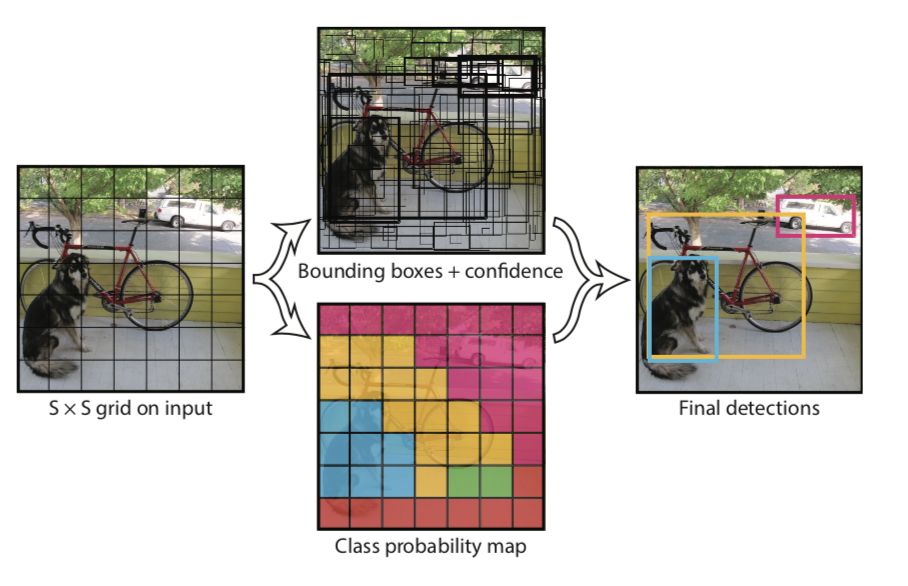 YOLOv1整体结构
YOLOv1整体结构
 虽然综述读起来累些,但多读综述有利于知识体系的梳理。而且NLP领域的综述读多了会发现,很多优化方法都是相通的,也能提供一些新的思路。
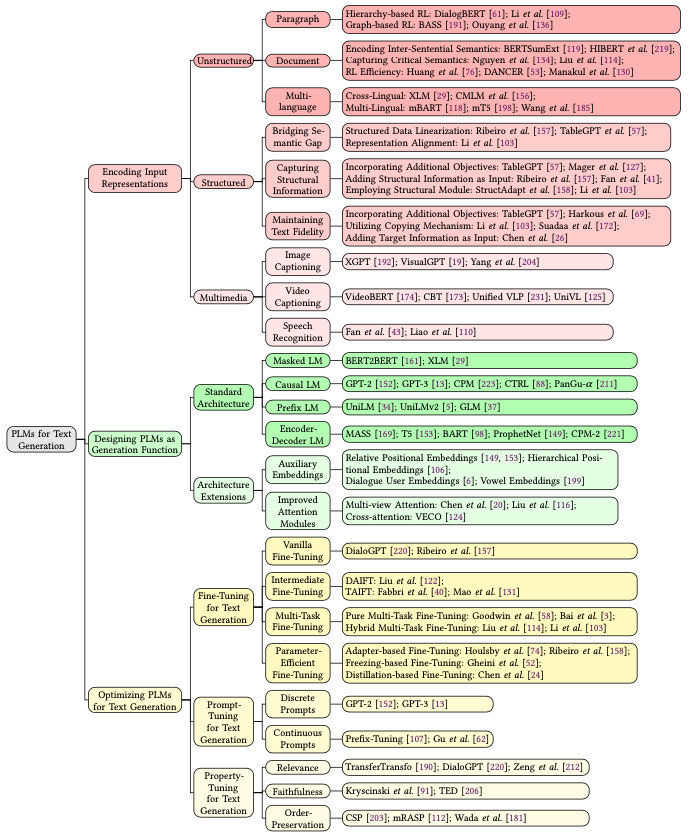
这篇文章从把文本生成的方法分成了三类:输入编码、模型设计、优化方法。同时也从数据、模型、优化层面给出了下面我们就顺着文章的思路,梳理一下最近几年文本生成领域的进展。
虽然综述读起来累些,但多读综述有利于知识体系的梳理。而且NLP领域的综述读多了会发现,很多优化方法都是相通的,也能提供一些新的思路。
这篇文章从把文本生成的方法分成了三类:输入编码、模型设计、优化方法。同时也从数据、模型、优化层面给出了下面我们就顺着文章的思路,梳理一下最近几年文本生成领域的进展。