Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks; 论文地址:https://arxiv.org/abs/1908.10084; 论文代码:https://github.com/UKPLab/ sentence-transformers。
Introduction
Bert模型已经在NLP各大任务中都展现出了强者的姿态。在语义相似度计算(semantic textual similarity)任务上也不例外,但是,由于bert模型规定,在计算语义相似度时,需要将两个句子同时进入模型,进行信息交互,这造成大量的计算开销。例如,有10000个句子,我们想要找出最相似的句子对,需要计算(10000*9999/2)次,需要大约65个小时。Bert模型的构造使得它既不适合语义相似度搜索,也不适合非监督任务,比如聚类。
在实际应用中,例如:在问答系统任务中,往往会人为地配置一些常用并且描述清晰的问题及其对应的回答,我们将这些配置好的问题称之为“标准问”。当用户进行提问时,常常将用户的问题与所有配置好的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。如果使用bert模型,那么每一次一个用户问题过来,都需要与标准问库计算一遍。在实时交互的系统中,是不可能上线的。
解决聚类和语义搜索的一种常见方法是将每个句子映射到一个向量空间,使得语义相似的句子很接近。通常获得句子向量的方法有两种:
1.计算所有Token输出向量的平均值
2.使用[CLS]位置输出的向量
然而,UKP的研究员实验发现,在文本相似度(STS)任务上,使用上述两种方法得到的效果却差强人意,即使是Glove向量也明显优于朴素的BERT句子embeddings(见下图前三行)
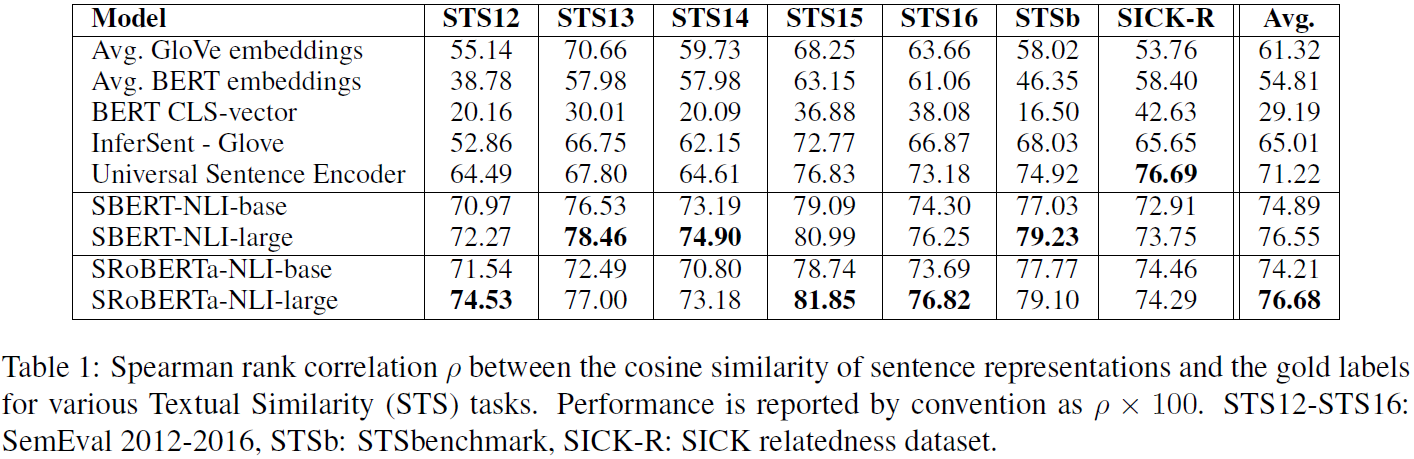
而作者提出了Sentence-BERT网络结构来解决bert模型的不足。简单通俗地讲,就是借鉴孪生网络模型的框架,将不同的句子输入到两个bert模型中(但这两个bert模型是参数共享的,也可以理解为是同一个bert模型),获取到每个句子的句子表征向量;而最终获得的句子表征向量,可以用于语义相似度计算,也可以用于无监督的聚类任务。对于同样的10000个句子,我们想要找出最相似的句子对,只需要计算10000次,需要大约5秒就可计算完全。 从65小时到5秒钟,这真是恐怖的差距。
Model
下面我们详细介绍一些Sentence-BERT网络结构,作者在文中定义了三种通过bert模型求句子向量的策略,分别是CLS向量,平均池化和最大值池化。
CLS向量策略,就是将bert模型中,开始标记【cls】向量,作为整句话的句向量。
平均池化策略,就是将句子通过bert模型得到的句子中所有的字向量进行求均值操作,最终将均值向量作为整句话的句向量。
最大值池化策略,就是将句子通过bert模型得到的句子中所有的字向量进行求最大值操作,最终将最大值向量作为整句话的句向量。
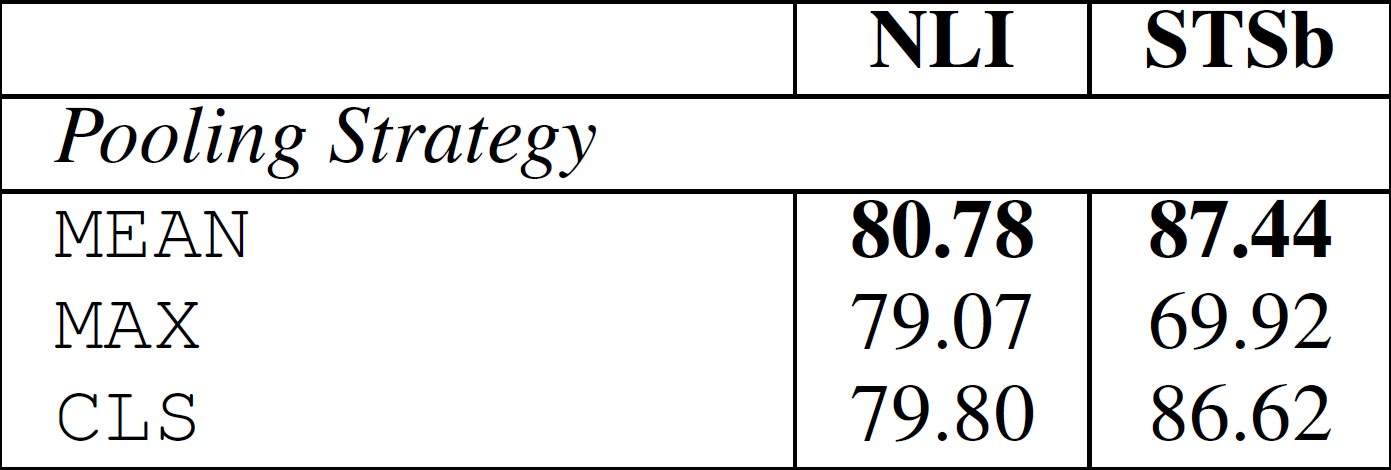
由结果可见,MEAN的效果是最好的,所以后面实验默认采用的也是MEAN策略
并且作者在对bert模型进行微调时,设置了三个目标函数,用于不同任务的训练优化;
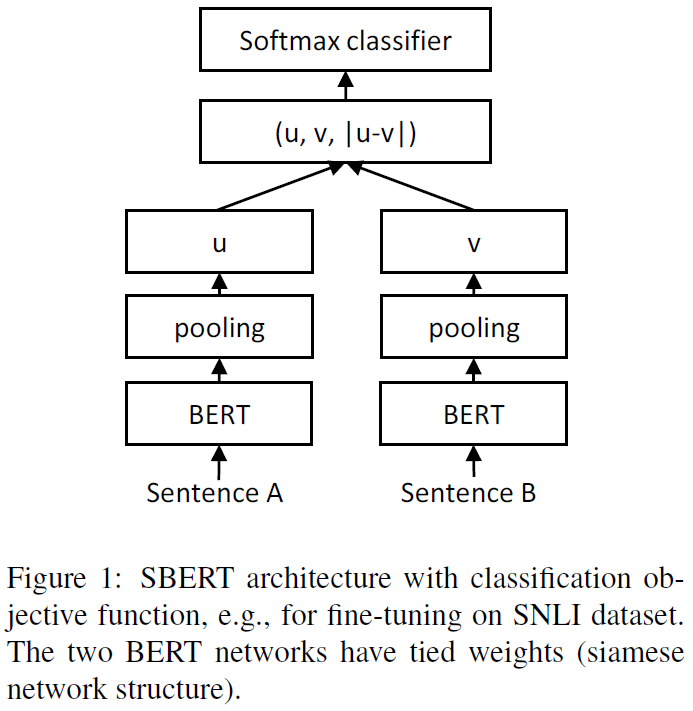
1.Classification Objective Function
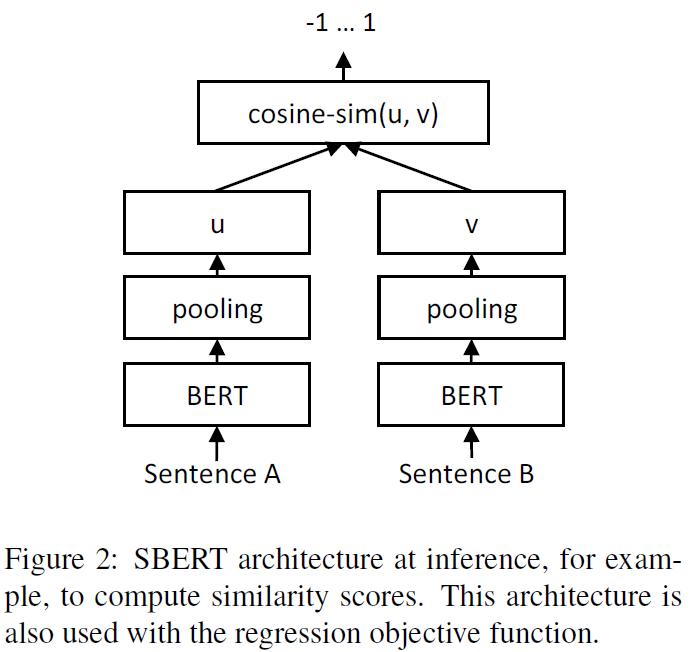
2.Regression Objective Function
两个句子embedding向量 u , v的余弦相似度计算结构如下所示,损失函数为MAE(mean squared error)
3.Triplet Objective Function
给定一个主句 a ,一个正面句子 p和一个负面句子 n ,三元组损失调整网络,使得 a 和 p之间的距离尽可能小, a 和 n之间的距离尽可能大。数学上,我们期望最小化以下损失函数:
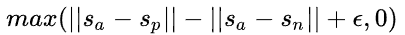
模型训练细节
作者训练时结合了SNLI(Stanford Natural Language Inference)和Multi-Genre NLI两种数据集。SNLI有570,000个人工标注的句子对,标签分别为矛盾,蕴含(eintailment),中立三种;MultiNLI是SNLI的升级版,格式和标签都一样,有430,000个句子对,主要是一系列口语和书面语文本
蕴含关系描述的是两个文本之间的推理关系,其中一个文本作为前提(Premise),另一个文本作为假设(Hypothesis),如果根据前提能够推理得出假设,那么就说前提蕴含假设。参考样例如下:
 实验时,作者使用类别为3的softmax分类目标函数对SBERT进行fine-tune,batch_size=16,Adam优化器,learning_rate=2e-5
实验时,作者使用类别为3的softmax分类目标函数对SBERT进行fine-tune,batch_size=16,Adam优化器,learning_rate=2e-5
消融研究
为了对SBERT的不同方面进行消融研究,以便更好地了解它们的相对重要性,我们在SNLI和Multi-NLI数据集上构建了分类模型,在STS benchmark数据集上构建了回归模型。在pooling策略上,对比了MEAN、MAX、CLS三种策略;在分类目标函数中,对比了不同的向量组合方式。结果如下
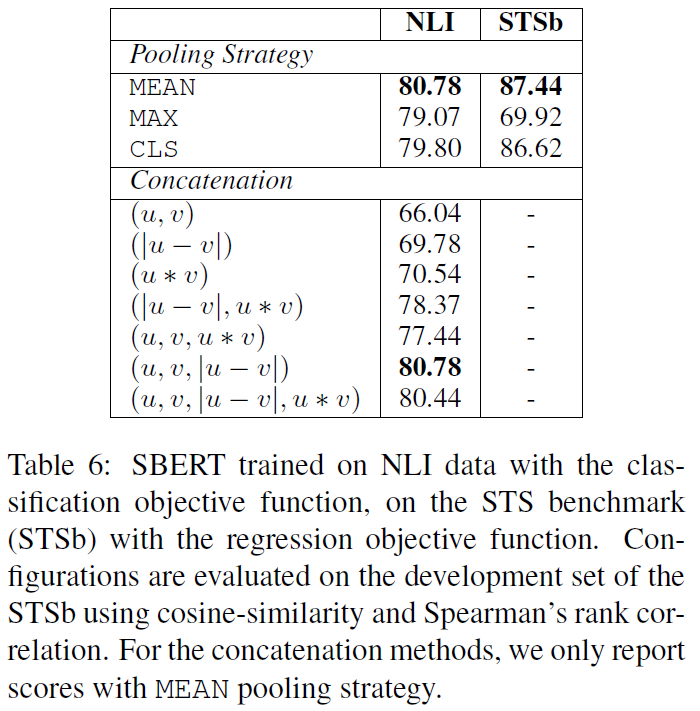 结果表明,Pooling策略影响较小,向量组合策略影响较大,并且 [u;v;∣u−v∣]效果最好
结果表明,Pooling策略影响较小,向量组合策略影响较大,并且 [u;v;∣u−v∣]效果最好
QUESTIONS
1.为什么速度会快? n个句子做n个bert推理,得到n个句子向量就可以了。剩下的就是向量距离的计算。这个计算量小。直接进bert的话,要n平方的bert推理。 2.为什么mean pooling比cls好 从实验结果得出