47-转置卷积
本节目录
1.转置卷积
- 转置卷积和卷积的区别:
- 卷积不会增大输入的高宽,通常要么不变、要么减半
- 转置卷积则可以用来增大输入高宽
- 转置卷积的具体实现:
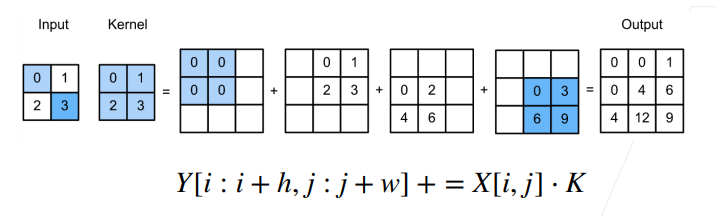 如图所示,input里的每个元素和kernel相乘,最后把对应位置相加,相当于卷积的逆变换
如图所示,input里的每个元素和kernel相乘,最后把对应位置相加,相当于卷积的逆变换
- 为什么称之为“转置:
- 对于卷积Y=X*W
- 可以对W构造一个V,使得卷积等价于矩阵乘法Y'=VX'
- 这里Y',X'是Y,X对应的向量版本
- 转置卷积等价于Y'=VTX'
- 如果卷积将输入从(h,w)变成了(h‘,w’)
- 同样超参数的转置卷积则从(h‘,w’)变成为(h,w)
- 对于卷积Y=X*W
 主要分为五部
主要分为五部