CPU和GPU
本节目录:
1.1 提升CPU利用率一:
- 在计算a+b之前,需要准备数据
主内存->L3->L2->L1->寄存器
- L1访问延时:0.5ms
- L2访问延时:7ns(14XL1)
- 主内存访问延
作者文章归档:justlin_01
主内存->L3->L2->L1->寄存器
深层神经网络的训练,尤其是使网络在较短时间内收敛是十分困难的,批量归一化[batch normalization]是一种流行且有效的技术,能加速深层网络的收敛速度,目前仍被广泛使用。
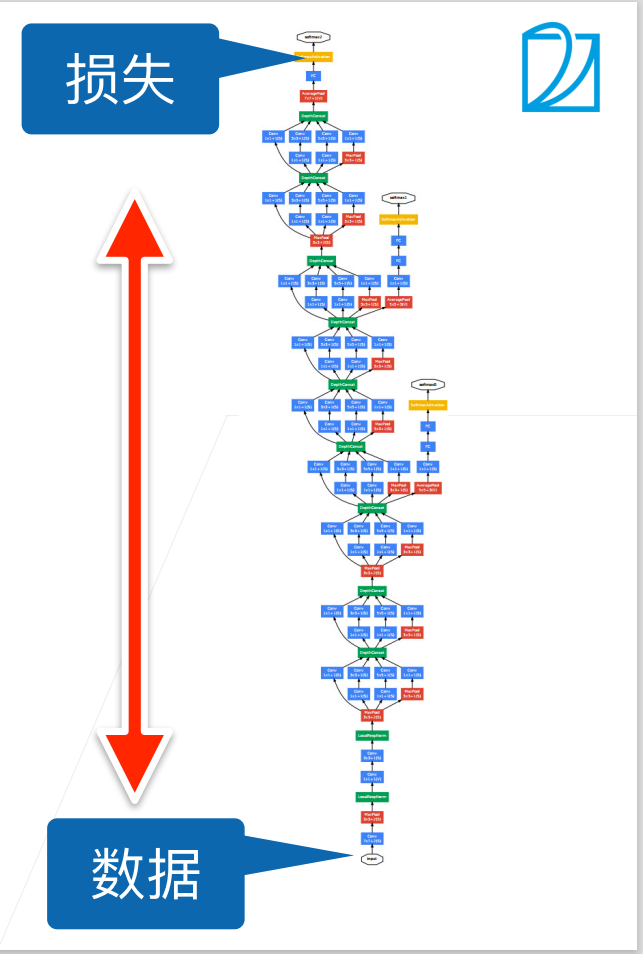
深度神经网络在训练时会遇到一些问题:

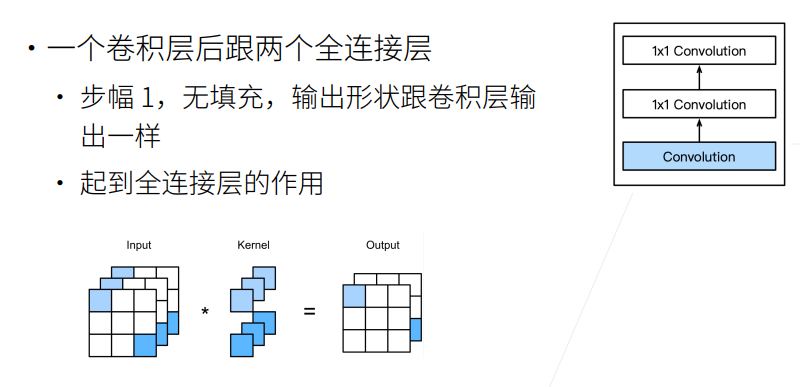
全连接层的问题

以VGG为例(图示),全连接层需要先Flatten,输入维度为512x7x7,输出维度为4096,则需要参数个数为512x7x7x4096=102M。
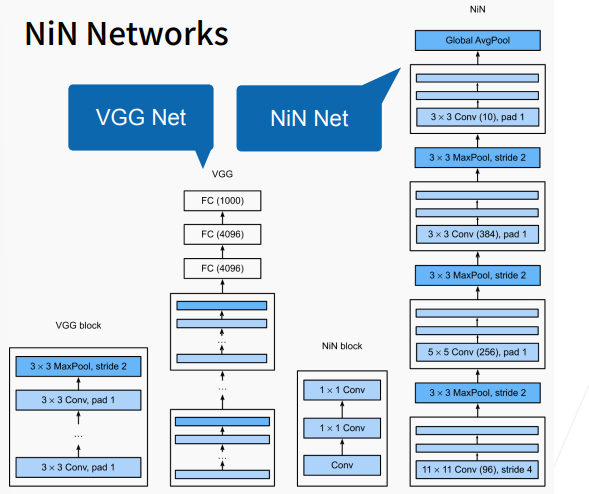
NiN架构如上图右边所示,若干个Ni
Alexnet最大的问题在于长得不规则,结构不甚清晰,也不便于调整。想要把网络做的更深更大需要更好的设计思想和标准框架。
直到现在更深更大的模型也是我们努力的方向,在当时AlexNet比LeNet更深更大得到了更好的精度,大家也希望把网络做的更深更大。选择之一是使用更多的全连接层,但全连接层的成本很高;第二个选择是使用更多的卷积层,但缺乏好的指导思想来说明在哪加,加多少。最终VGG采取了将卷积层组合成块,再把卷积块组合到一起的思路。
VGG块可以看作是AlexNet思路的拓展,A


#导入所需的库
import本节将介绍池化(pooling)层,它具有目的:类似于数据增强,降低卷积层对位置的敏感性;一定程度减少计算。
与卷积层类似,池化层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口遍历的每个位置计算一个输出。 然而,不同于卷积层中的输入与卷积核之间的互相关计算,池化层不包含参数。 相反,池运算符是确定性的,我们通常计算池化窗口中所有元素的最大值或平均值。这些操作分别称为最大池化层(maximum pooling)和平均池化层(average pooling)。
在这两种情况下,与互相关运算符一样,池化窗口从输入张量的左上角
彩色图像可能有RGB三个通道
转换为灰度会丢失信息

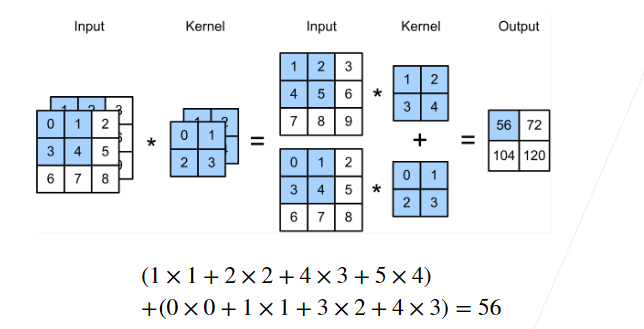
多个输入通道:
import torch
from d2l import torch as d2l
def corr2d_multi_in(X, K):
return sum(d2l.corr2d(x, k