35-分布式训练
本节目录
1.分布式计算
- 本质上来说和之前讲的单机多卡并行没有区别。二者之间的区别是分布式计算是通过网络把数据从一台机器搬到另一台机器
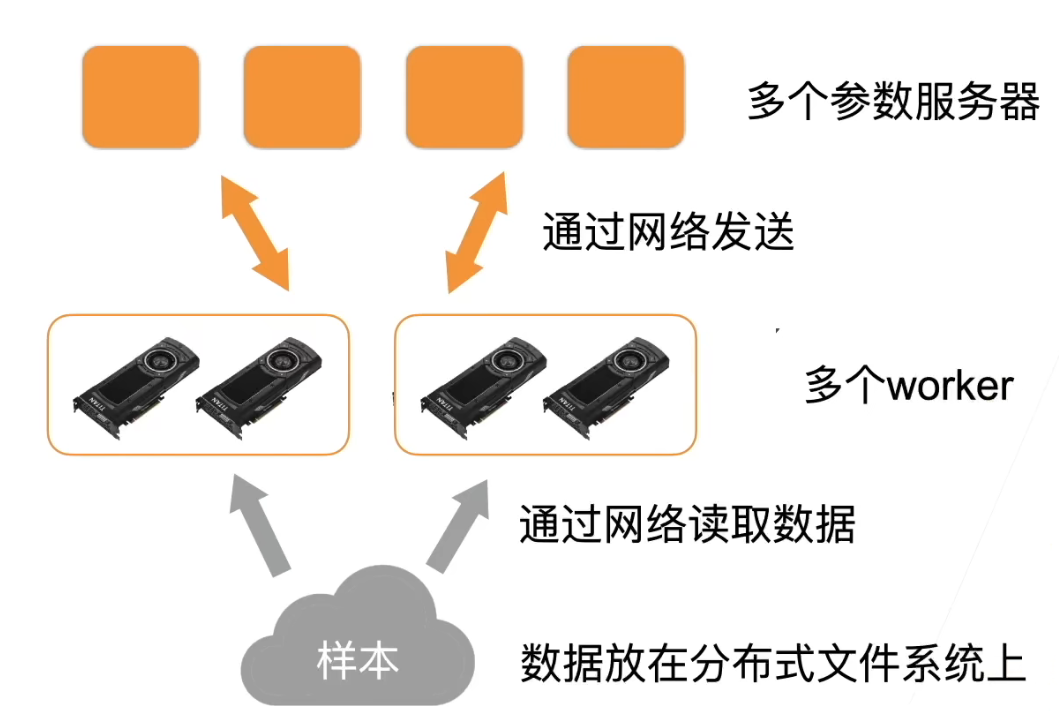
2. GPU机器架构
- 总的来说,gpu到gpu的通讯是很快的,gpu到cpu慢一点。机器到机器更慢。因而总体性能的关键就是尽量在本地做通讯而少在机器之间做通讯
2.1 样例:计算一个小批量
- 每个worker从参数服务器那里获取模型参数:首先把样本复制到机器的内存,然后把样本分到每个gpu上
- 复制参数到每个gpu上:同样,先把每一次的参数放到内存里,然后再复制到每个gpu上
- 每个gpu计算梯度
- 再主内存上把所有gpu上的梯度加起来
- 梯度从主内存传回服务器
- 每个服务器对梯度求和,并更新参数
2.2 总结
- 由于gpu到gpu和gpu到内存的通讯速度还不错,因此我们尽量再本地做聚合(如梯度相加),并减少再网络上的多次通讯
3. 关于性能
3.1 对于同步SGD:
- 这里每个worker都是同步计算一个批量,称为同步SGD
- 假设有n个ggpu,每个gpu每次处理b个样本,那么同步SGD等价于再单gpu运行批量大小为nb的SGD
- 再理想情况下,n个gpu可以得到相对单gpu的n倍加速
3.2 性能:
- t1 = 在单gpu上计算b个样本梯度时间
- 假设有m个参数,一个worker每次发送和接受m个参数、梯度
- t2 = 发送和接受所用时间
- 每个批量的计算时间为max(t1,t2)
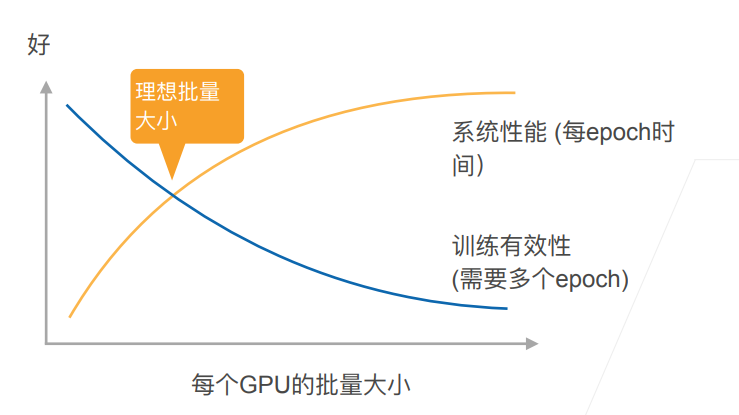
- 选取足够大的b使t1>t2
- 增加b或n导致更大的批量 大小,当值需要更多计算来得到给定的模型精度
3.3 性能的权衡
4. 实践时的建议
- 使用一个大数据集
- 需要好的gpu-gpu和机器-机器带宽
- 高效的数据读取和预处理
- 模型需要有好的计算和通讯比
- Inception>ResNet>AlexNet
- 使用足够大的批量大小来得到更好的系统性能
- 使用高效的优化算法对应大批量大小
5. 总结
- 分布式同步数据并行是多gpu数据并行在多机器上的拓展
- 网络通讯通常是瓶颈
- 需要注意使用特别大的批量大小时的收敛效率
- 更复杂的分布式有异步、模型并行(这里没有介绍)
34 多GPU训练实现QA
本讲内容为代码实现,这里整理QA,其余内容参考代码部分。
Q1: keras从tf分离,书籍会不会需要重新整理?
暂时不会有影响
Q2: 是否可以通过把resnet中的卷积层全替换成mlp来实现一个很深的网络?
可以,有这样做的paper,但是通过一维卷积(等价于全连接层)做的,如果直接换成全连接层很可能会过拟合。
Q3: 为什么batch norm是一种正则但只加快训练不提升精度?
老师也不太清楚并认为这是很好的问题,可以去查阅论文。
Q4: all_reduce, all_gather主要起什么作用?实际使用时发现pytorch的类似分布式op不能传导梯度,会破坏计算图不能自动求导,如何解决?
all_reduce是把n个东西加在一起再把所有东西复制回去,all_gather则只是把来自不同地方东西合并但不相加。使用分布式的东西会破坏自动求导,跨GPU的自动求导并不好做,老师不确定pytorch能不能做到这一功能,如果不能就只能手写。
Q5: 两个GPU训练时最后的梯度是把两个GPU上的梯度相加吗?
是的。mini-batch的梯度就是每个样本的梯度求和,多GPU时同理,每个GPU向将自己算的那部分样本梯度求和,最后再将两个GPU的计算得的梯度求和。
Q6: 为什么参数大的模型不一定慢?flop数多的模型性能更好是什么原理?
性能取决于每算一个乘法需要访问多少个bit,计算量与内存访问的比值越高越好。通常CPU/GPU不会被卡在频率上而是访问数据/内存上,所以参数量小,算力高的模型性能较好(如卷积,矩阵乘法)。
Q7: 为什么分布到多GPU上测试精度会比单GPU抖动大?
抖动是因为学习率变大了,使用GPU数对测试精度没有影响,只会影响性能。但为了得到更好的速度需要把batchsize调大,使得收敛情况发生变化,把学习率上调就使得精度更抖。
Q8: batchsize太大会导致loss nan吗?
不会,batchsize中的loss是求均值的,理论上batchsize更大数值稳定性会更好,出现数值不稳定问题可能是学习率没有调好。
Q9: GPU显存如何优化?
显存手动优化很难,靠的是框架,pytorch的优化做的还不错。除非特别懂框架相关技术不然建议把batchsize调小或是把模型做简单一点。
Q10: 对于精度来说batchsize=1是一种最好的情况吗?
可能是。
Q11: parameter server可以和pytorch结合吗,具体如何实现?
pytorch没有实现parameter server,但mxnet和tensorflow有。但是有第三方实现如byteps支持pytorch。
Q12: 用了nn.DataParallel(),是不是数据集也被自动分配到了多个GPU上?
是的。在算net.forward()的时候会分开。
Q13: 验证集准确率震荡大那个参数影响最大?
学习率。
Q14: 为了让网络前几层能够训练能否采用不同stage采用不同学习率的方法?
可以,主要的问题是麻烦,不好确定各部分学习率相差多少。
Q15: 在用torch的数据并行中将inputs和labels放到GPU0是否会导致性能问题,因为这些数据最终回被挪一次到其他GPU上。
数据相比梯度来说很少,不会对性能有太大影响。但这个操作看上去的确很多余,老师认为不需要做,但不这样做会报错。
Q16: 为什么batchsize较小精度会不怎么变化?
学习率太大了,batchsize小学习率就不能太大。
Q17: 使用两块不同型号GPU影响深度学习性能吗?
需要算好两块GPU的性能差。如一块GPU的性能是另一块的2倍,那么在分配任务时也应该分得2倍的任务量。保证各GPU在同样时间内算完同一部分。
Q18: 课内竞赛直接用教材的VGG11但不收敛,同样的dataloader用resnet可以收敛,如何解决这一问题?
可能是学习率太大,也可考虑加入batch normalization。