导读:在互联网新零售的大背景下,商品知识图谱作为新零售行业数字化的基石,提 供了对于商品相关内容的立体化、智能化、常识化的理解,对上层业务的落地起到了 至关重要的作用。相比于美团大脑中围绕商户的知识图谱而言,在新零售背景下的商 品知识图谱需要应对更加分散、复杂的数据和业务场景,而这些不同的业务对于底层 知识图谱都提出了各自不同的需求和挑战。美团作为互联网行业中新零售的新势力, 业务上已覆盖了包括外卖、商超、生鲜、药品等在内的多个新零售领域,技术上在相 关的知识图谱方面进行了深入探索。本文将对美团新零售背景下零售商品知识图谱的 构建和应用进行介绍。
01 商品图谱背景
1. 美团大脑
近年来,人
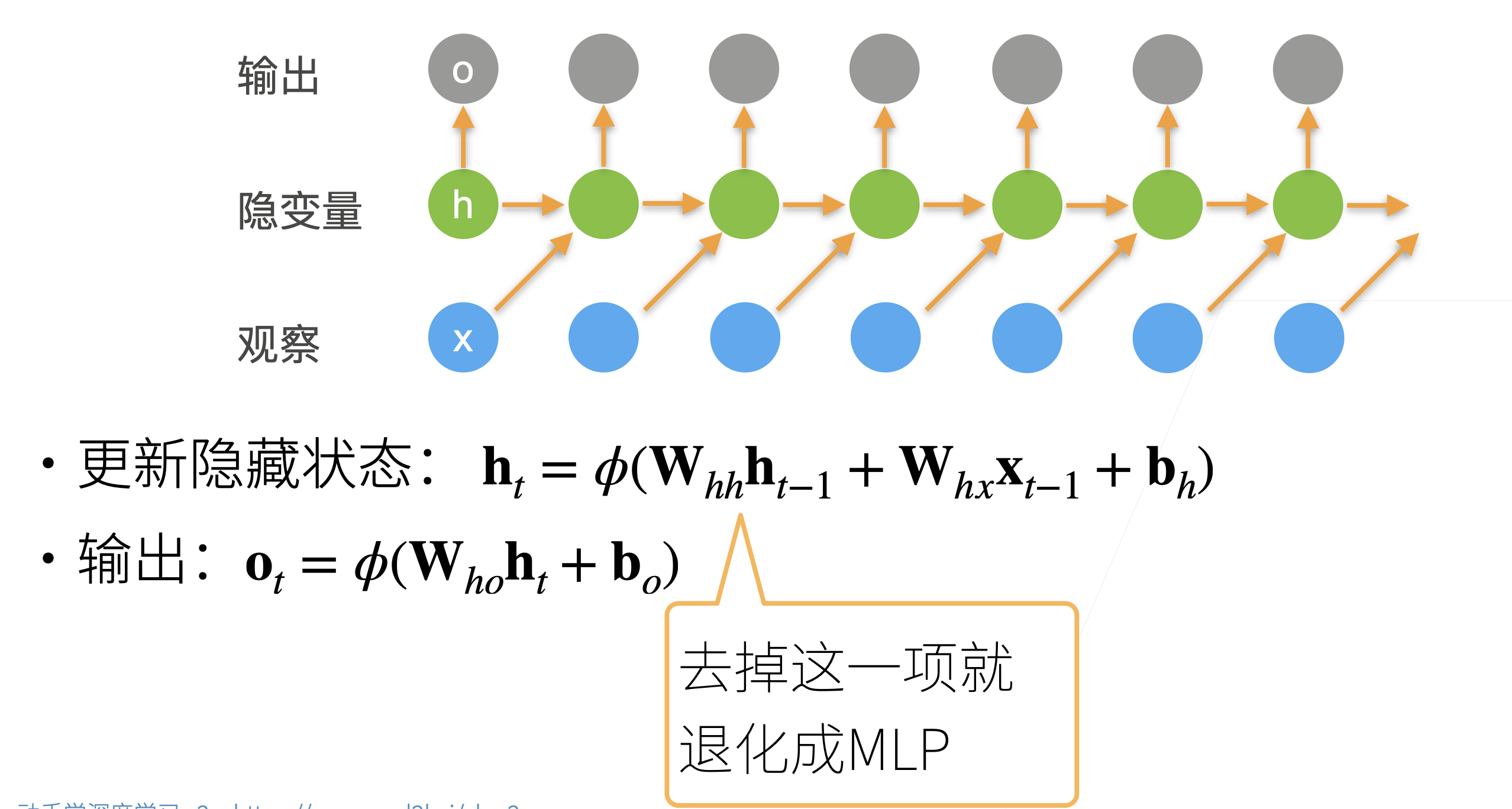
 (课程视频中的图片有错误,最后输出层后一时间步是不受前一步影响的,即没有箭头)
(课程视频中的图片有错误,最后输出层后一时间步是不受前一步影响的,即没有箭头)