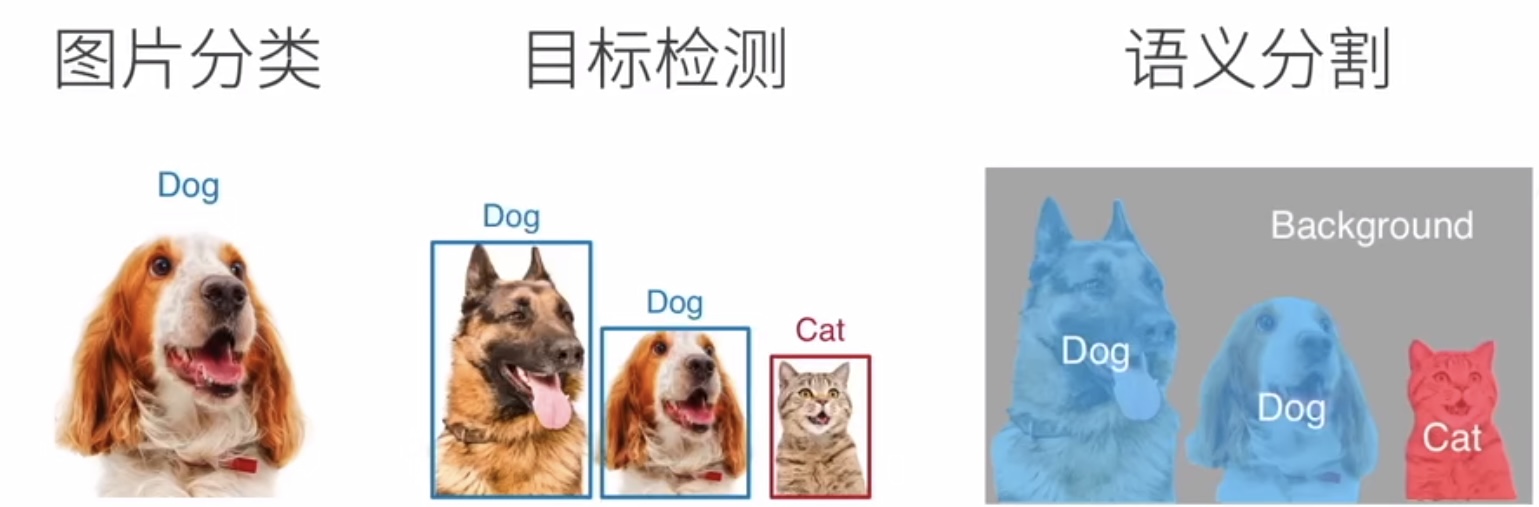
使用潜变量
- RNN使用了隐藏层来记录过去发生的所有事件的信息,从而引入时许的特性,并且避免常规序列模型每次都要重新计算前面所有已发生的事件而带来的巨大计算量。

RNN
- 流程如下,首先有一个输入序列,对于时刻t,我们用t-1时刻的输入x~t-1~和潜变量h~t-1~来计算新的潜变量h~t~。同时,对于t时刻的输出o~t~,则直接使用h~t~来计算得到。注意,计算第一个潜变量只需要输入即可(因为前面并不存在以往的潜变量)。
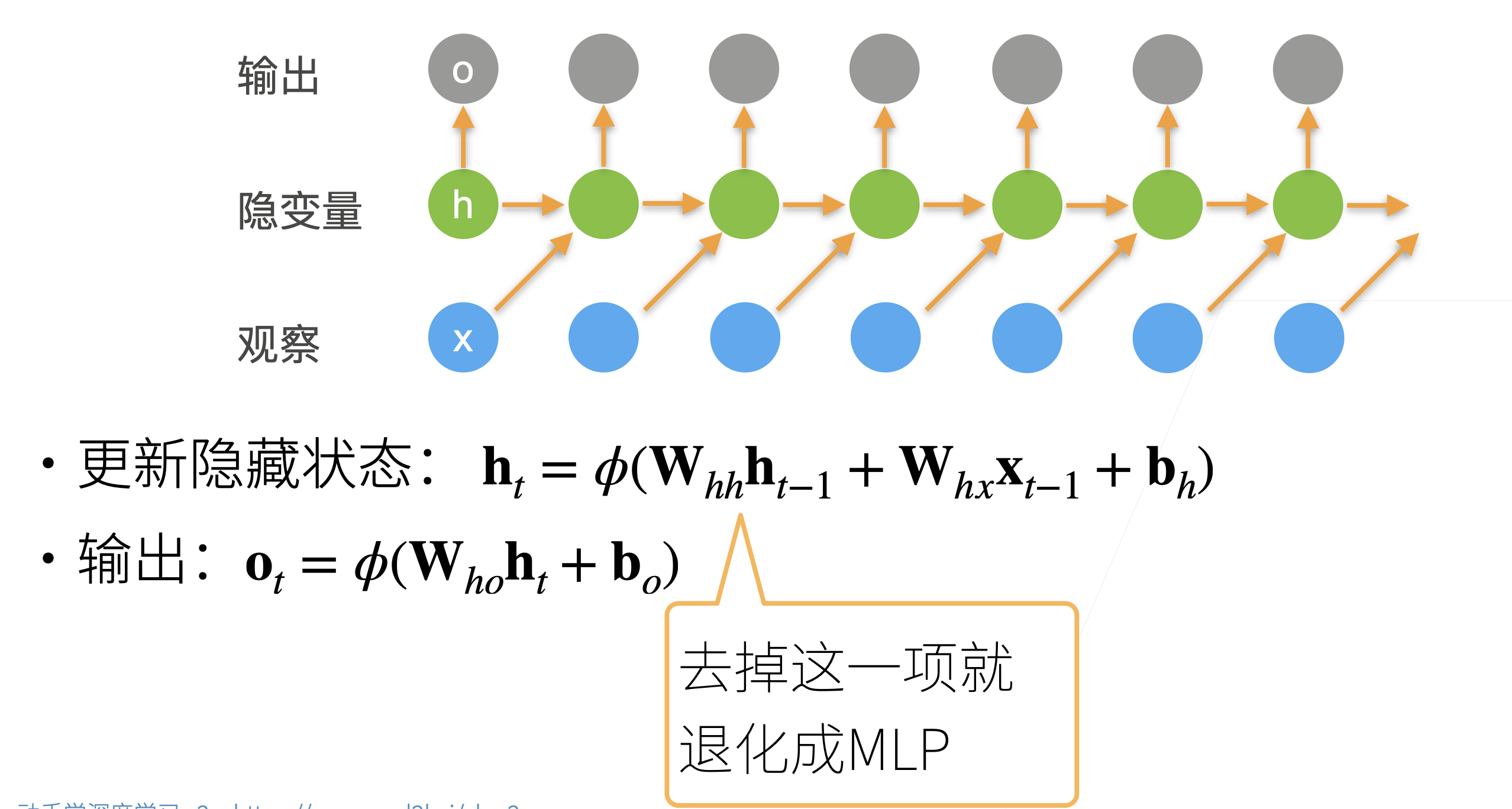
- 值得注意的是,RNN本质也是一种MLP,尤其是将h~t-1~这一项去掉时就完全退化成

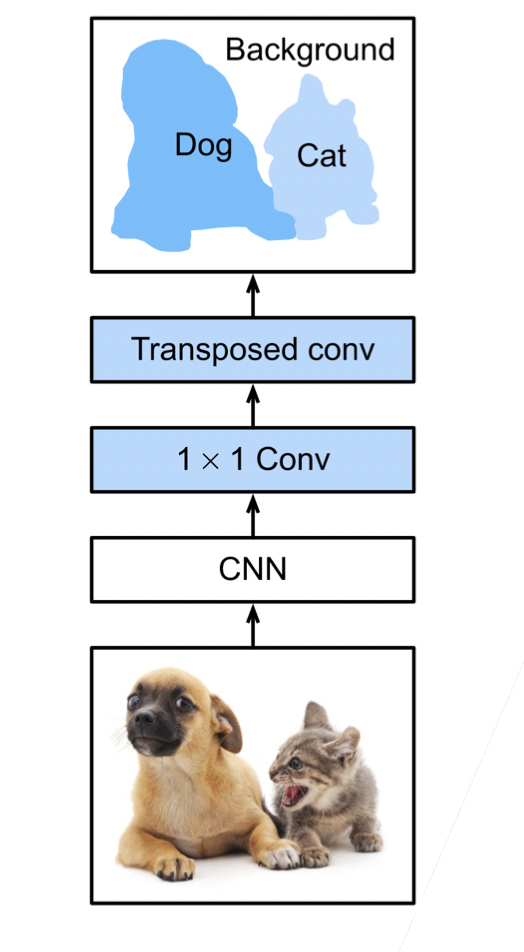
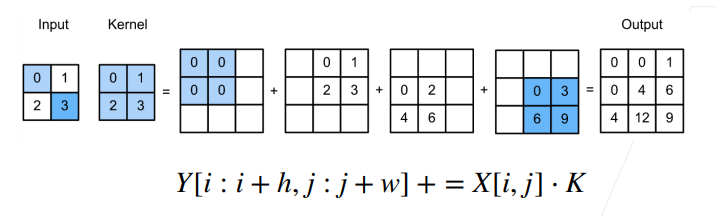 如图所示,input里的每个元素和kernel相乘,最后把对应位置相加,相当于卷积的逆变换
如图所示,input里的每个元素和kernel相乘,最后把对应位置相加,相当于卷积的逆变换