前言
这篇文章梳理下目前命名实体识别(NER)的业务场景与SOTA方法。 说到NER,是绕不开BERT+CRF的,根据本人的经验,BERT+CRF就算不是你当前数据集的SOTA,也与SOTA相差不大了,但考虑到 更好的效果:CRF虽然引入了无向图,但只约束了相连结点之间的关联,并没有从全局出发来考虑问题 更复杂的业务场景:如Flat NER到Nested NER、不连续NER等复杂业务场景的不断涌现,CRF是否还能优雅地解决问题 更快的线上serving效率:CRF解码复杂度与输入的文本长度呈线性关系 本文,首先梳理下场景,再讨论方法,欢迎大家交流。
场景
嵌套(Nested)
组间嵌套:如上图中的“隔离妆前乳”,既属于品类,也属于产品名的一部分 组内嵌套:如上图的“妆前乳”,既是单独一个品类,也属于品类“隔离妆前乳”的一部分
不连续
如上图的“苏菲娜控油隔离妆前乳”就为不连续的产品名,因为这里希望提取出的产品名是一个标准的产品名,因此中间一些无关的信息,如“限定款”不希望被抽取出来
范式一:BERT+CRF
嵌套与不连续
BERT+CRF怎么解决嵌套和不连续的场景呢?答案是分层CRF和万能的标签大法(schema tagging)。如下图所示
 解决组间嵌套的方式就是共享BERT,但训练多个CRF层
解决组间嵌套的方式就是共享BERT,但训练多个CRF层
解决组内嵌套通过设计标签,如品类那行的N标签,表示处于某个品类的中间部分,同时也是某个品类的开头
解决不连续通过设计标签,如产品名那行的G标签,表示token处于不连续产品名的中间部分,这部分输出时是要舍弃的 可以看到,其实BERT+CRF也是可以很灵活的。
范式二:Multi-Head(token pairs based)
Multi-Head,用头token与尾token的来表示一段span(所以称为token pairs),再接一些交互层和分类层,得到Multi-head(多头)矩阵。
数字表达式是 f(hi,hj,t) =score,其中 h为BERT的输出, score表示i 和j 的文本片段在第 t 个实体类上的得分。
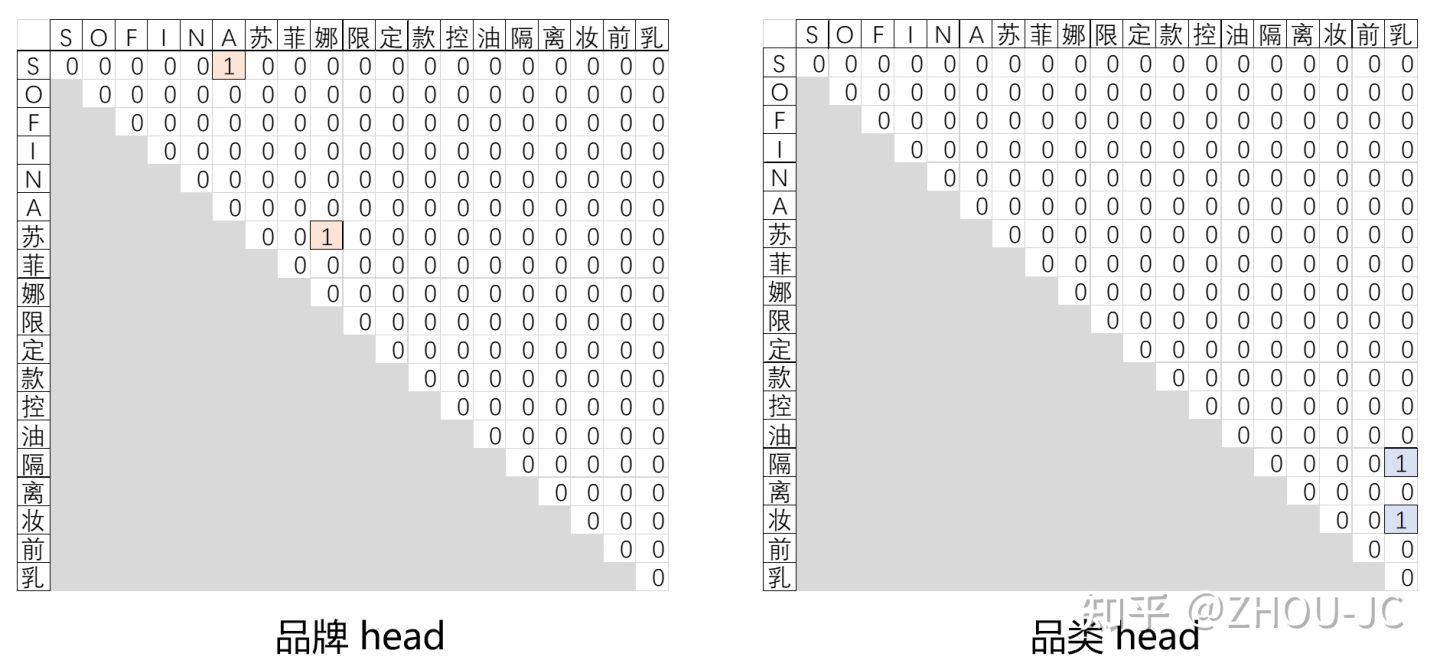 如上图的品牌head矩阵(0,5)位置为1,表示"SOFINA"为品牌。
如上图的品牌head矩阵(0,5)位置为1,表示"SOFINA"为品牌。
嵌套与不连续
容易看到,Multi-Head能天然解决组间嵌套和组内嵌套问题。
解决不连续问题也可以通过设置head来相对优雅地进行解决,如这里设置多一个“产品名中间”的head,把产品名中间也当成一种实体提取出来,然后用提取出的产品名减去与它index有重叠的产品名中间,即可得到不连续的产品名。

构建 [L, L, N]多头矩阵的不同方式(乘性、加性、双仿射)
Multi-head最终得到的是一个[L,L,N]矩阵(这里忽略batch_size维度),其中L是输入的文本长度,N是实体类型数的,但怎么得到呢?这里介绍三种常见的方法 乘性 《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》[1] 加性 《Joint entity recognition and relation extraction as a multi-head selection problem》[2] 双仿射 《Named Entity Recognition as Dependency Parsing》[3]
位置信息
在NER任务中,位置信息,特别是相对位置非常重要,实验中发现,相对位置信息对于Multi-head这种token pairs based的模式更为重要,一句话总结:告诉模型start token与end token之间的距离非常关键。 举个例子,一段文本 欧莱雅新出的护肤系列里面的精华液很贵,但是乳液十分便宜 正常要提取的品类是“精华液”和“乳液”,但假如不加入位置信息,模型很容易会把“精华液很贵,但是乳液”也识别成品类,原因是token pairs这种模式,用"精"和"液"表示这段span,模型看到会觉得"精"和“液”很像是品类的头和尾,但模型不知道其实这段span是很长的,中间已经参杂了很多无用的信息。 因此,单纯靠在BERT输入端加入的绝对位置信息对于这种复杂场景来说,还不够,必须在靠近输出端再加入一层相对位置信息。 对于乘性算子,可以考虑苏神提出的旋转式位置编码,对于加行算子,可以在[B, L, L, 2*H]中加入相对位置信息,具体不在这里展开。
标签不平衡
多头矩阵存在大量的0标签,训练出来的模型很可能会高精确低召回,解决之道是通过改损失函数(如Focal Loss、Label Weight等)、负采样等方式来缓解这种不平衡。
这种比较推荐负采样,因为负采样还能缓解NER任务中的一大噪声——漏标。
对于垂直领域,漏标实在太常见了,在论文《Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition》[5]中提到,漏标对于训练出来的NER模型性能伤害是很大的,其实可以拿自己手头的NER数据做一些简单的实验,例如:
数据集一:数据量5K,漏标率10%
数据集二:数据量10K,漏标率20%
看看多出来一倍的数据量,是否能弥补多出来的10%漏标率。个人感觉是,漏标对于BERT+CRF这种以序列解码方式的模型来说影响是很大的。而多头怎么解决这种漏标呢?
答案很简单,负采样,如下图的"苏菲娜"漏标了,本来矩阵的(7,9)位置应该是1的,但现在gold label是0,通过负采样,不把这个loss来进行反向传播就完事了,那这个漏标就不会对参数更新造成影响。
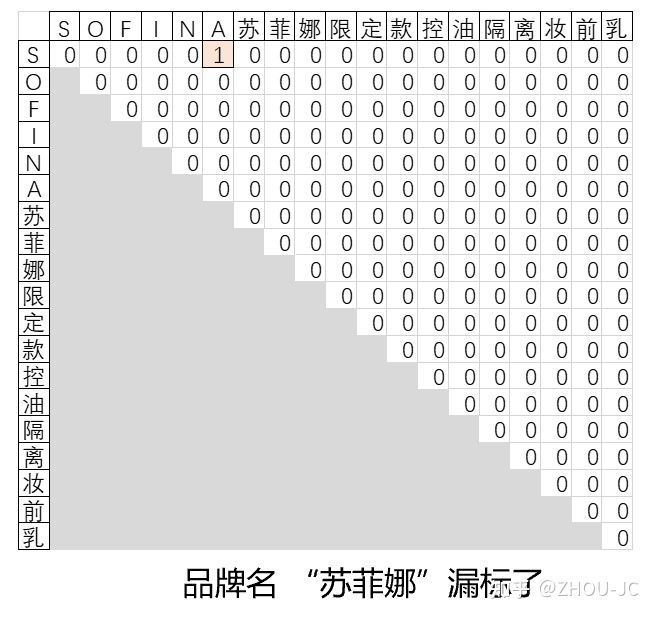 至于负采样多少比较好?这个可能要依据你手头的数据集而定,有些论文会说每个输入文本采样100个负样本,在论文[5]实验中,采样个数为文本长度的0.3~0.4效果最好,总的来说,需要做实验得到这个超参。
Sigmoid or Softmax?
在多头中,损失函数的通常有两种选择
Softmax:构造(实体类型数+1)个head的多头矩阵,其中一个head代表null entity,最后在head的维度上做softmax
至于负采样多少比较好?这个可能要依据你手头的数据集而定,有些论文会说每个输入文本采样100个负样本,在论文[5]实验中,采样个数为文本长度的0.3~0.4效果最好,总的来说,需要做实验得到这个超参。
Sigmoid or Softmax?
在多头中,损失函数的通常有两种选择
Softmax:构造(实体类型数+1)个head的多头矩阵,其中一个head代表null entity,最后在head的维度上做softmax
Sigmoid:构造(实体类型数)个head的多头矩阵,每个元素单独做sigmoid
通常来说,Softmax会比Sigmoid效果更好,训练速度更快,因为Softmax还融入了类间的互斥信息。
范式三:BERT+MRC
把NER任务当成机器阅读理解(MRC)任务来处理,把要提取的实体类型信息,显式地加入到输入中,如下图所示,预测的start和end即为对应实体的start和end。

统一信息抽取任务的范式
用MRC来做NER可以看香侬科技的两篇论文: 《Entity-relation extraction as multi-turn question answering》[6] 《A Unified MRC Framework for Named Entity Recognition》[7] 何谓统一呢?个人理解统一意味着用同一个模型架构来解决信息抽取的三大任务(命名实体识别、关系识别、事件抽取),做任务迁移时参数是完全可迁移的,不像BERT+CRF,做任务迁移的时候,要重新训练一个CRF层。 因此有个美好的设想,可以用公开的数据集、公司所有的信息抽取数据集先“预热”一个通用的机器阅读理解模型,以后有新任务来的时候,说不定只标3K~4K条数据就可以媲美标上万条数据的效果。
解决嵌套与不连续
MRC天然能解决组间嵌套的问题,
处理组内的嵌套,还需要多一步,就是计算一个类似“多头”的矩阵,与Multi-head不同的是,这里只有一个head,而且它是与entity type是无关的,因此也是可迁移的,与下图所示。

 处理不连续问题,可以通过设置question来解决,如下图所示。
处理不连续问题,可以通过设置question来解决,如下图所示。

实体信息的知识增强
MRC比BERT+CRF和Multi-Head的优势在哪呢? 一方面,可以利用大量的数据来预热
另一方面,把entitiy的信息encode到输入端(即question中),有助于模型更“懂”要抽取的实体 因此,question的构造就显得十分重要了,这里提供几种方式构建question。 Pseudo question:伪问题,如品牌;品类;产品名 Rule-based template filling:基于模型的问题,如请抽取文中的品牌;请抽取文中的品类;请抽取文中的产品名 Annotation guideline notes:用标注规范的标注说明来表示问题,如 美妆(彩妆、护肤、美容仪器、香水、配套工具)、日化(日用化学品)等商品的品牌 美妆(彩妆、护肤、美容仪器、香水、配套工具)、日化(日用化学品)等品类商品,如口红、面膜、脱毛仪、古龙水、化妆刷 完整的美妆(彩妆、护肤、美容仪器、香水、配套工具)、日化(日用化学品)产品名称
提高计算效率 & 提高知识注入的强度
用MRC来做NER的诟病就是计算效率太低,有N个entity type,就需要在BERT前向计算N次。
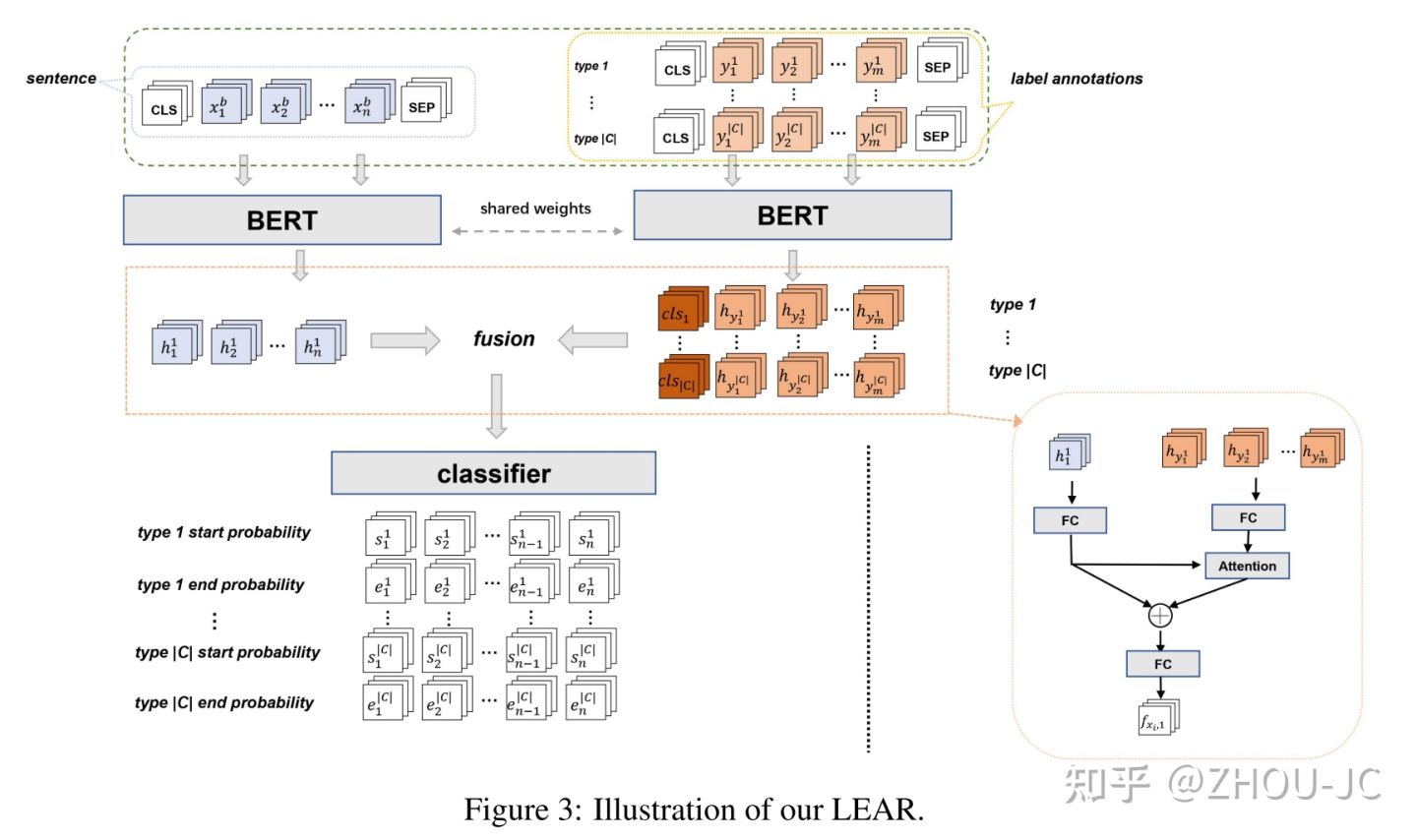
在2021年EMNLP的一篇论文《Enhanced Language Representation with Label Knowledge for Span Extraction》[8]中,提出了叫LEAR的模型架构,如下图所示。
本质就是不把question与context在BERT的输入端进行拼接,而是question和context分别前向,然后再经过一个fusion模块来进行交互,好处是,线上serving的时候,question的embedding只需要计算一次,要预测的每个context也只需要前向一次了。
那这种方式,会不会造成性能的损害呢?毕竟,原始的MRC是question与context从头交互到尾,而LEAR则只是靠近输出端交互。
论文的解释是不会,如下图所示,原始的MRC,例如现在求“judge”的attention,发现与question的交互并不紧密,大部分attention还是集中于context自身,而LEAR设计的fusion模块有一步是让context的token只能与question的token产生交互。

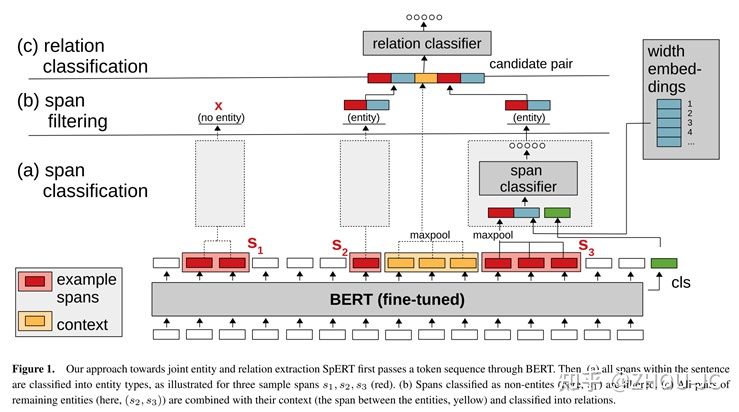
范式四:Span-based
《 Span-based Joint Entity and Relation Extraction with Transformer Pre-training 》[9],区别于token pairs用头和尾token来表示这段span,span-based是用span的每个token做pooling来表示这段span,可以猜测的是,这种表征方式肯定要比token pairs要好。
但span-based貌似无法设计成并行的模式,时间复杂度太高!
总结
本文从实际场景出发,讨论了不同NER的范式,并给出不同方法的tricks细节,不过值得注意的是,采用哪种方式需要结合场景,举个例子 场景一:想省心,就用BERT+CRF吧,BERT+CRF的好处是没有太多超参,只需要注意CRF层的学习率要比BERT调大一些,如大100倍左右 场景二:手头的任务是很垂直的领域,能获得的数据集有大量的漏标,这种情况不妨尝试Multi-Head+负采样的方式,能缓解噪声的影响 场景三:有大量相似的数据集,希望能利用起来,此时就可以选择BERT+MRC这种统一的范式