近年来YOLO系列层出不穷,更新不断,已经到v7版本。本人认为不能简单用版本高低来评判一个系列的效果好坏,YOLOv1-v7不同版本各有特色,在不同场景,不同上下游环境,不同资源支持的情况下,如何从容选择使用哪个版本,甚至使用哪个特定部分,都需要我们对YOLOv1-v7有一个全面的认识。 故本人将YOLO系列每个版本都表示成下图中的五个部分,逐一进行解析,并将每个部分带入业务侧,竞赛侧,研究侧进行延伸思考,探索更多可能性。 【Make YOLO Great Again】YOLOv1-v7全系列大解析(Neck篇)已经发布,大家可按需取用~ 而本文将聚焦于Head侧的分享,希望能让江湖中的英雄豪
YOLOv1-v7全系列大解析(Head篇)
发表评论
1053 views
 虽然综述读起来累些,但多读综述有利于知识体系的梳理。而且NLP领域的综述读多了会发现,很多优化方法都是相通的,也能提供一些新的思路。
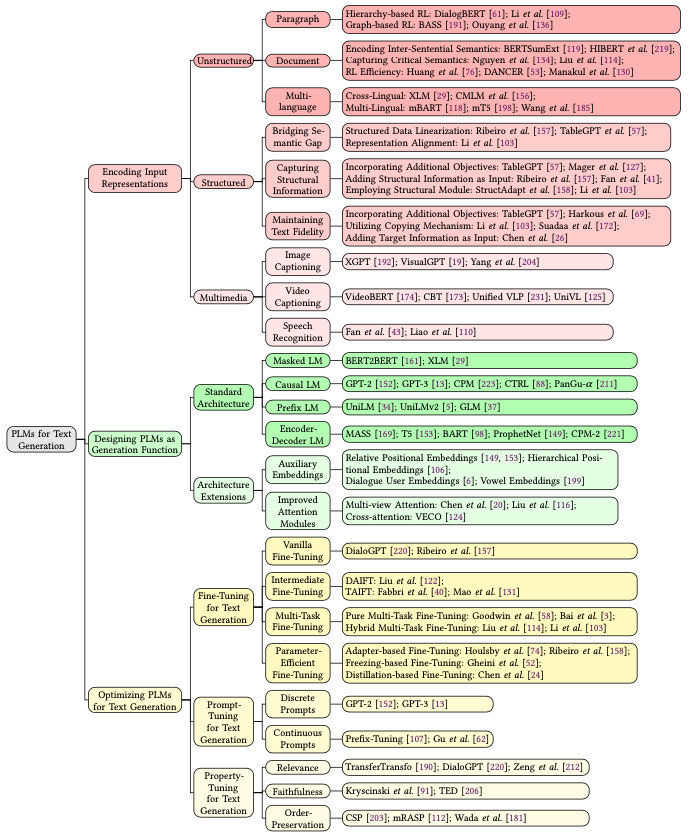
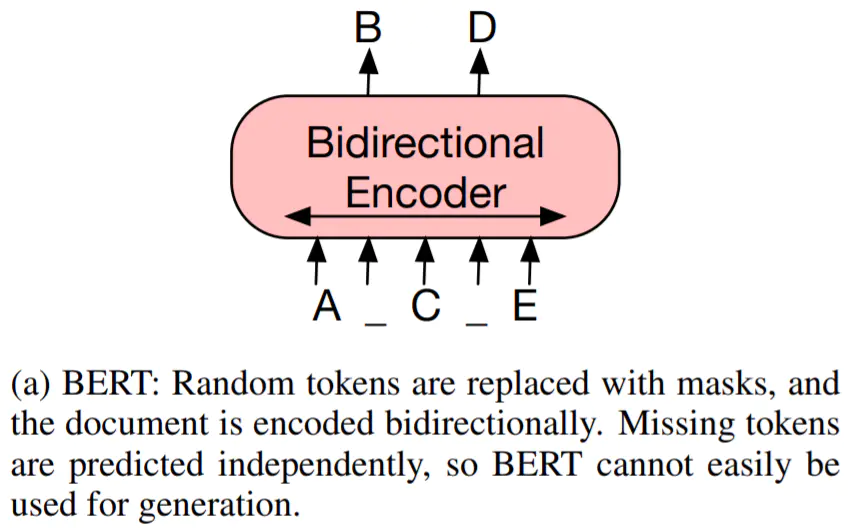
这篇文章从把文本生成的方法分成了三类:输入编码、模型设计、优化方法。同时也从数据、模型、优化层面给出了下面我们就顺着文章的思路,梳理一下最近几年文本生成领域的进展。
虽然综述读起来累些,但多读综述有利于知识体系的梳理。而且NLP领域的综述读多了会发现,很多优化方法都是相通的,也能提供一些新的思路。
这篇文章从把文本生成的方法分成了三类:输入编码、模型设计、优化方法。同时也从数据、模型、优化层面给出了下面我们就顺着文章的思路,梳理一下最近几年文本生成领域的进展。