导读:目前百度事件图谱已构建了千万级规模的事件图谱,在收录时效上达到分钟级。 事件图谱技术已应用到搜索、信息流等百度内部的产品中,相关能力也对外输出到媒 体等多个行业。另外,事件图谱的前沿推理技术在金融领域的探索也初步取得成果, 并已形成一个金融事件归因和预测的推理平台。本文将为大家详细介绍百度的事件图 谱技术与应用,主要内容包括: 事件图谱概述 事件图谱技术 事件图谱应用 总结与展望
01 事件图谱概述
1. 知识图谱
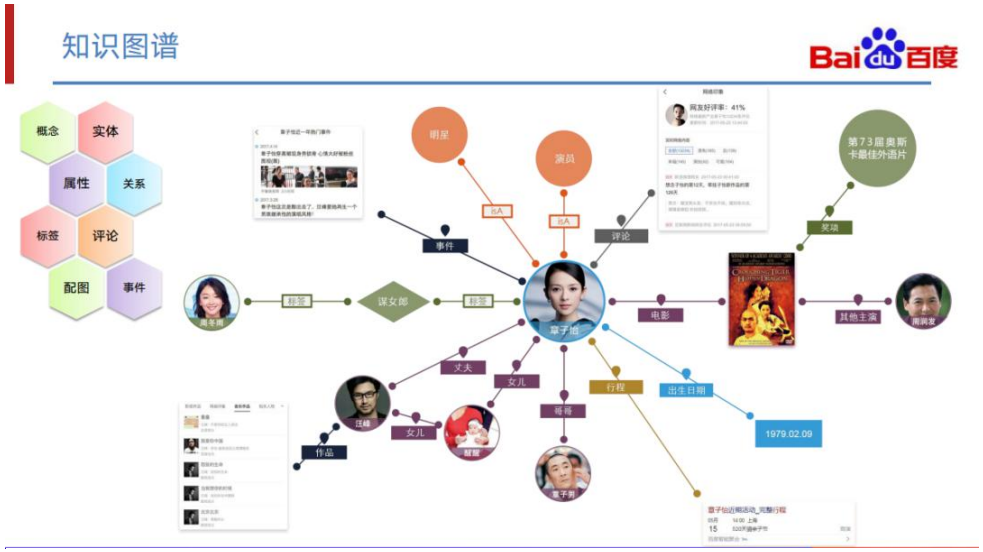
知识图谱构建的目的,其实是为了把世界上纷繁复杂的、各种各样的客观事实通过图 谱的方式组织起来,让机器能够通过这个图谱更好地实现理解、抽取、推理等任务, 从而提升我们处理信息的效率。最基础的知识图谱包含实体、关系、属性等图谱最核 心的知识,而更广义的知识图谱则包含更多的知识,如概念、标签、评论等。事件也 是一种知识,一种比较复杂的知识。事件知识的复杂性在于事件并不会对应到现实世 界中的某一个具体的实体,它是一系列实体,以不同的角色在一段时间内参与活动的 一个抽象。 百度于 2017 年底就开始了事件图谱方向的研究。经过了三年的发展,目前已经在多 个不同的方向和领域落地。
2. 事件图谱
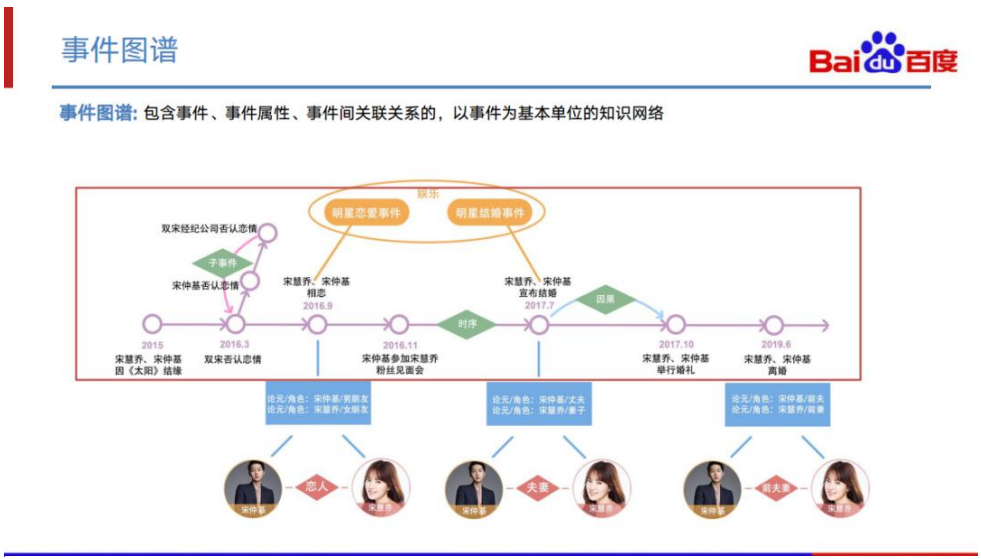 事件图谱是什么?事件图谱是包含事件、事件属性、事件间关联关系的以事件为基本 单位的知识网络。上图是以宋仲基、宋慧乔从相恋到结婚、再到离婚这么一系列事件 及其相关内容所组成的事件图谱的示意图。每个事件都有自己的事件类型,不同的事 件类型拥有着不同的角色。如双宋结婚事件,它在事件图谱中的内容就是,一个结婚 类型的事件,这个类型的事件有两个角色,其中,丈夫角色的值是宋仲基,而妻子角 色的值是宋慧乔。事件之间的关系也在事件图谱的构建范围内,包括时序、因果、从 属等。除了事件图谱的内容外,在上图中,我们还可以看到事件图谱与实体图谱是有 对应关系的,事件的发生是可能会触发实体与实体间关系或属性的变化的,例如,上 面的例子中,结婚事件的发生导致了双宋的关系从男女朋友关系变成丈夫与妻子的关 系。
事件图谱是什么?事件图谱是包含事件、事件属性、事件间关联关系的以事件为基本 单位的知识网络。上图是以宋仲基、宋慧乔从相恋到结婚、再到离婚这么一系列事件 及其相关内容所组成的事件图谱的示意图。每个事件都有自己的事件类型,不同的事 件类型拥有着不同的角色。如双宋结婚事件,它在事件图谱中的内容就是,一个结婚 类型的事件,这个类型的事件有两个角色,其中,丈夫角色的值是宋仲基,而妻子角 色的值是宋慧乔。事件之间的关系也在事件图谱的构建范围内,包括时序、因果、从 属等。除了事件图谱的内容外,在上图中,我们还可以看到事件图谱与实体图谱是有 对应关系的,事件的发生是可能会触发实体与实体间关系或属性的变化的,例如,上 面的例子中,结婚事件的发生导致了双宋的关系从男女朋友关系变成丈夫与妻子的关 系。
3. 为什么要做事件图谱?
 为什么要做事件图谱?有两个方面原因:
第一方面,事件其实更符合人类对客观世界的理解。例如,以桃园三结义这幅图为例。 在没有知识或弱知识的时候,我们可以知道这幅图里有三个人,有酒和树。在有实体 知识的时候,我们可以知道这三个人的姓名是刘备、关羽和张飞,树是桃树。直到拥 有事件知识的时候,我们才可以知道具体时间在东汉末年,刘备、关羽和张飞三个人 在桃园做了结义这一个事情。我们可以看到,只有到事件这个层次上,才能说真正对 这幅画有一个比较完整的把握。 另一方面,事件图谱可以对动态的客观世界进行建模。实体图谱会记录了实体的属性 和关系,当实体的属性或关系更新时,图谱只会保留它最新的状态。但通过事件图谱, 我们能够对属性或关系的整个变化过程进行建模,并且可以将这些事件与变化的进行 一一对应。
为什么要做事件图谱?有两个方面原因:
第一方面,事件其实更符合人类对客观世界的理解。例如,以桃园三结义这幅图为例。 在没有知识或弱知识的时候,我们可以知道这幅图里有三个人,有酒和树。在有实体 知识的时候,我们可以知道这三个人的姓名是刘备、关羽和张飞,树是桃树。直到拥 有事件知识的时候,我们才可以知道具体时间在东汉末年,刘备、关羽和张飞三个人 在桃园做了结义这一个事情。我们可以看到,只有到事件这个层次上,才能说真正对 这幅画有一个比较完整的把握。 另一方面,事件图谱可以对动态的客观世界进行建模。实体图谱会记录了实体的属性 和关系,当实体的属性或关系更新时,图谱只会保留它最新的状态。但通过事件图谱, 我们能够对属性或关系的整个变化过程进行建模,并且可以将这些事件与变化的进行 一一对应。
4. 事件图谱是事件处理智能化的关键
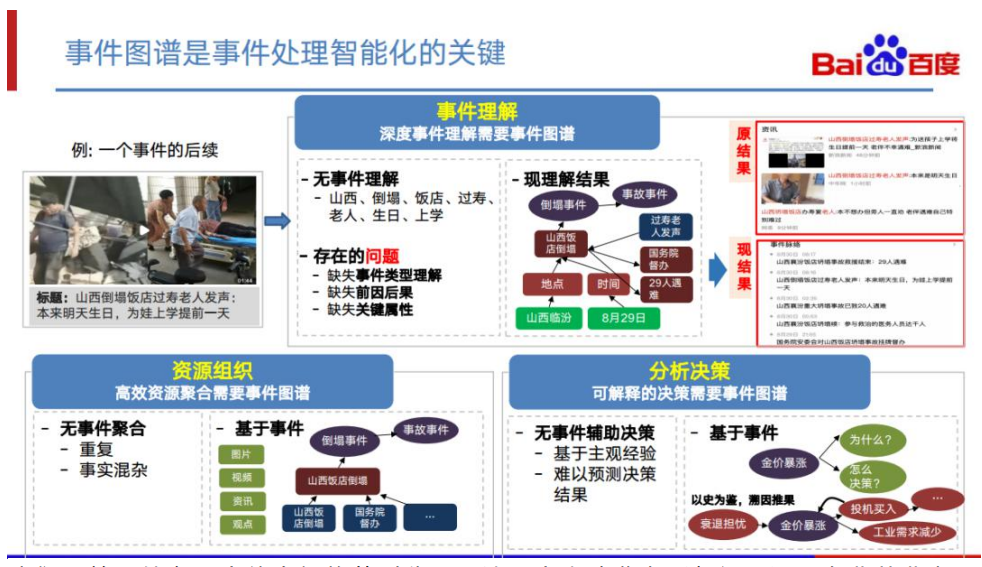 我们目前正处在一个信息爆炸的时代,无论是个人消费者看新闻,还是专业从业者跟 进行业事件消息,我们都不可避免地受到信息过载的影响。一方面存在太多无意义的 信息分散了我们的注意力,另一方面当我们关注某个事件时,却又无法快速、全面地 获得信息。怎么样去智能化地对事件进行处理,帮助我们更高效的获取和处理事件信 息呢?关键就是事件图谱。智能地对事件进行处理的三个方面:事件理解、资源组织、 分析决策都需要事件图谱。
事件理解:以“山西饭店倒塌事件”为例,如果没有事件图谱,我们只能得到 与这个单独的事件相关的内容。而通过事件图谱,我们还能得到它的一些后续 事件,如“国务院督办”等。基于这样一种事件级别的理解,我们就可以把原 来只是聚焦于一个单一事件的内容升级为对事件的上下文、前因后果都能联系 起来的一种事件脉络的呈现,从而大大提升用户获取事件信息的效率。
资源组织:在没有事件图谱的情况下,事件的信息载体通常是新闻资讯,这些 新闻资讯常常存在重复、角度不一、来源混杂的情况。在事件图谱的基础上, 我们可以将各种资源,包括图片、视频、资讯、观点等,围绕事件进行组织, 从而帮助用户更高效更全面地获取事件信息。
分析决策:在没有事件图谱辅助的情况下,决策常常是决策者结合现实情况和 主观经验做出的,在多数情况下,我们很难判断决策者是否已经考虑了所有的 现实情况,并且对未来可能发生的不同的方向进行了足够的考虑。而基于事件 图谱,我们能够让决策者清晰地了解一个事件可能的原因和结果,从而使决策 者能够做出更加全面及有根据的考虑。
我们目前正处在一个信息爆炸的时代,无论是个人消费者看新闻,还是专业从业者跟 进行业事件消息,我们都不可避免地受到信息过载的影响。一方面存在太多无意义的 信息分散了我们的注意力,另一方面当我们关注某个事件时,却又无法快速、全面地 获得信息。怎么样去智能化地对事件进行处理,帮助我们更高效的获取和处理事件信 息呢?关键就是事件图谱。智能地对事件进行处理的三个方面:事件理解、资源组织、 分析决策都需要事件图谱。
事件理解:以“山西饭店倒塌事件”为例,如果没有事件图谱,我们只能得到 与这个单独的事件相关的内容。而通过事件图谱,我们还能得到它的一些后续 事件,如“国务院督办”等。基于这样一种事件级别的理解,我们就可以把原 来只是聚焦于一个单一事件的内容升级为对事件的上下文、前因后果都能联系 起来的一种事件脉络的呈现,从而大大提升用户获取事件信息的效率。
资源组织:在没有事件图谱的情况下,事件的信息载体通常是新闻资讯,这些 新闻资讯常常存在重复、角度不一、来源混杂的情况。在事件图谱的基础上, 我们可以将各种资源,包括图片、视频、资讯、观点等,围绕事件进行组织, 从而帮助用户更高效更全面地获取事件信息。
分析决策:在没有事件图谱辅助的情况下,决策常常是决策者结合现实情况和 主观经验做出的,在多数情况下,我们很难判断决策者是否已经考虑了所有的 现实情况,并且对未来可能发生的不同的方向进行了足够的考虑。而基于事件 图谱,我们能够让决策者清晰地了解一个事件可能的原因和结果,从而使决策 者能够做出更加全面及有根据的考虑。
02 事件图谱技术
刚刚介绍了事件图谱的概述,包括是什么是事件图谱,为什么要做事件图谱。接下来 将进一步介绍事件图谱的关键技术:
1. 百度事件图谱技术概览
 这是百度事件图谱的技术概览图,主要分成四个层次:数据层、构建层、认知层和应 用层。本次分享的重点是事件图谱的构建层技术。
这是百度事件图谱的技术概览图,主要分成四个层次:数据层、构建层、认知层和应 用层。本次分享的重点是事件图谱的构建层技术。
2. 事件图谱构建
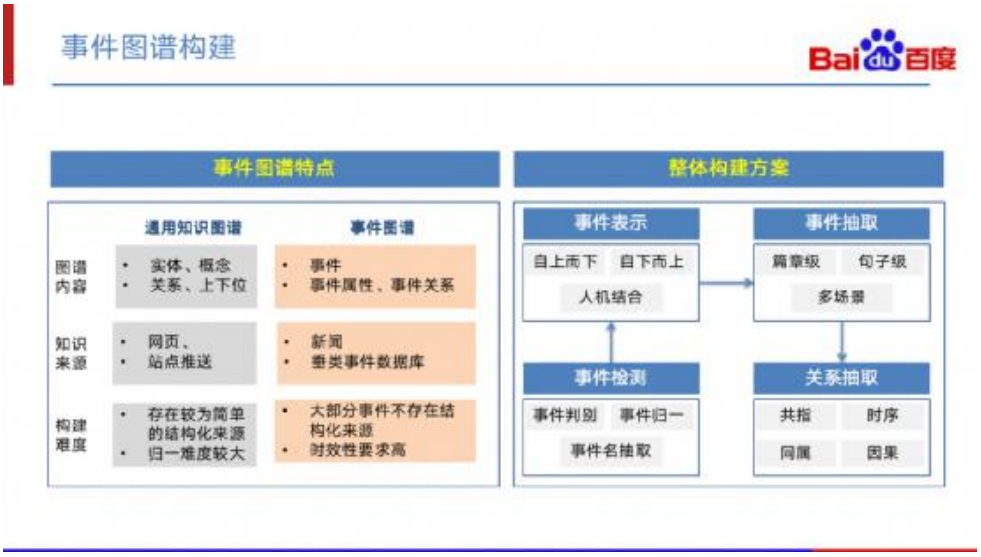 我先分享一下事件图谱跟传统的知识图谱在构建上的区别: 首先,就图谱的内容上而言,通用知识图谱主要包括实体、关系、概念、上下 位等,而事件图谱则主要包括事件、事件属性以及事件间的关系。 其次,就知识来源上而言,通用知识图谱常常存在一些优质的结构化来源 ( 如 垂类站点、百科等 ),而事件图谱的来源则主要是非结构化的新闻文本。 第三,在构建难度上,由于通用知识图谱存在结构化来源,知识相对来说是比 较容易进行抓取和构建的,构建主要的难度在于对不同来源的实体进行归一化。 而事件图谱则不太一样,绝大部分事件并不存在结构化来源,必须从新闻文本 中抽取,抽取难度更大。另外,事件图谱构建还有较高的时效性要求。 当前百度的事件图谱构建方案如下: 首先,进行事件检测。 其次,在事件检测的基础上归纳出事件表示体系。 最后,在事件表示体系的基础上进行事件抽取和关系抽取。 这个过程和传统知识图谱的构建不一样的地方在于:传统知识图谱会先将构建的 schema 定义出来,然后进行抽取与归一,最后再进行入库。而事件图谱由于缺少可 参考的结构化来源,需要先进行事件检测,在检测出大量事件的基础上,才能进行后 续的相关操作 ( 构建表示体系、抽取等 )。这是两者非常不同的一个地方。
我先分享一下事件图谱跟传统的知识图谱在构建上的区别: 首先,就图谱的内容上而言,通用知识图谱主要包括实体、关系、概念、上下 位等,而事件图谱则主要包括事件、事件属性以及事件间的关系。 其次,就知识来源上而言,通用知识图谱常常存在一些优质的结构化来源 ( 如 垂类站点、百科等 ),而事件图谱的来源则主要是非结构化的新闻文本。 第三,在构建难度上,由于通用知识图谱存在结构化来源,知识相对来说是比 较容易进行抓取和构建的,构建主要的难度在于对不同来源的实体进行归一化。 而事件图谱则不太一样,绝大部分事件并不存在结构化来源,必须从新闻文本 中抽取,抽取难度更大。另外,事件图谱构建还有较高的时效性要求。 当前百度的事件图谱构建方案如下: 首先,进行事件检测。 其次,在事件检测的基础上归纳出事件表示体系。 最后,在事件表示体系的基础上进行事件抽取和关系抽取。 这个过程和传统知识图谱的构建不一样的地方在于:传统知识图谱会先将构建的 schema 定义出来,然后进行抽取与归一,最后再进行入库。而事件图谱由于缺少可 参考的结构化来源,需要先进行事件检测,在检测出大量事件的基础上,才能进行后 续的相关操作 ( 构建表示体系、抽取等 )。这是两者非常不同的一个地方。
3. 事件检测
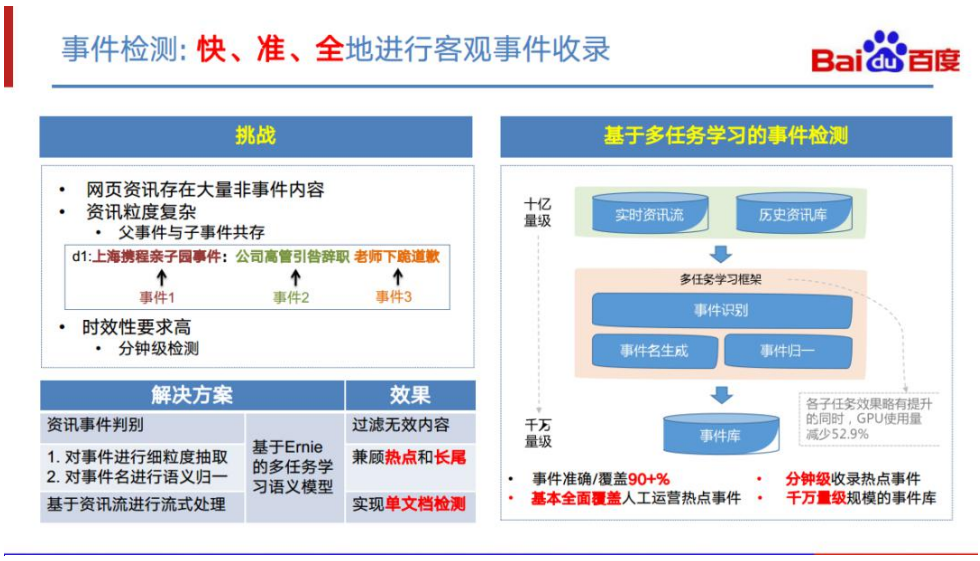
事件检测的目标是快、准、全地进行客观事件的收录,其主要挑战有三点: 第一,网页资讯存在大量的非事件内容。 第二,资讯的事件粒度是比较复杂的。父事件与子事件往往同时在同一篇网页 资讯中。我们用传统的方法,如聚类或资源突增的方法进行检测,很容易形成 一个很大的簇,同时容易将小的簇或较少提及的事件漏掉。 第三,几乎所有事件的应用场景对时效性的要求都比较高,大部分场景的事件 检测延迟需要达到分钟级。 我们的整体方案是一套基于多任务学习进行事件检测的流程。该流程主要分成三个部 分: 第一部分,我们会对信息流中的资讯进行事件识别,将非事件的内容排除在外。 第二部分,我们会对出现在资讯中的事件片段以事件名的形式抽取出来。 第三部分,我们会对事件进行归一。然后再将对应的资讯作为这个事件的资源 关联起来。 通过这个检测过程,只要一篇文档中有一部分提到了某个事件就可以进行事件收录, 结合百度的高时效新闻流,上面这种流程可以实现分钟级事件收录,并且整体的准确 率与覆盖率都可以到 90+%。此外,由于上述流程中涉及多个策略模型,我们还尝试 了多任务学习框架,上述所提及的多个策略模型在经过多任务学习后,能得到相互增 强,在资源消耗降低的同时,每个模型的效果都能得到进一步的提升。
4. 事件表示
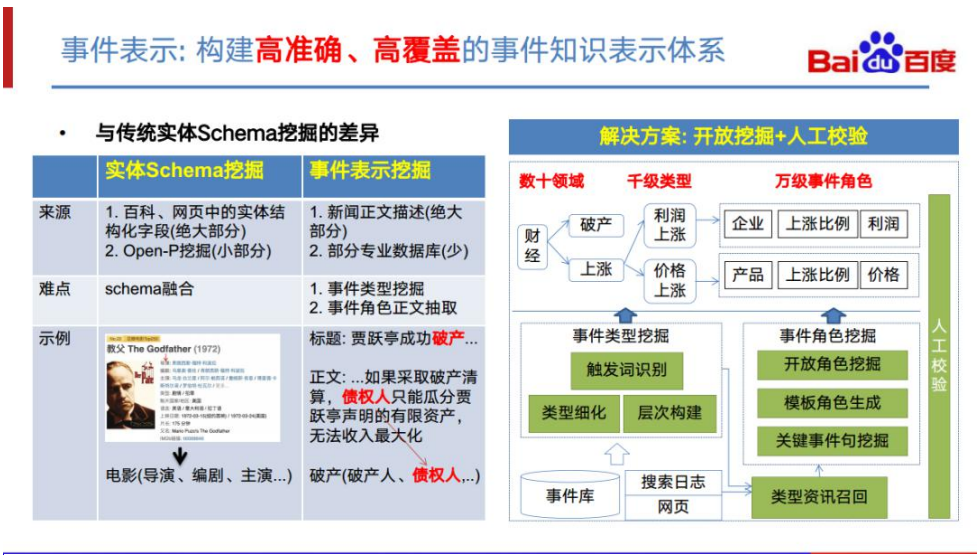
事件表示构建的目标是构建一个高准确、高覆盖的事件知识表示体系,以支持后面事 件抽取任务。在这一个任务上,它跟实体的 Schema 挖掘也是有明显差异的。实体 的 Schema 挖掘绝大部分来源于百科或是网页中的结构化字段,只有少部分可能会 涉及 Open-P 挖掘。以电影为例,这类实体很容易可以找到其对应实体的网页,如豆 瓣。从网页上我们就可以清晰地知道一个电影类型的实体会有哪些字段,例如,导演、 编剧、主演等。事件的表示就跟实体的 Schema 完全不同。绝大部分的事件类型其 实并不存在一个这样的垂类站点去做这件事情。 因此,我们必须从正文中去挖掘事件类型的属性。比如,“破产”这个事件类型。从 类型名可以知道该事件可能会有一个“破产人”属性,但是“债权人”这个属性就必 须从该类型相关的正文中才能找到。目前的解决方案是开放挖掘+人工校验。具体来 说分成下面几个部分。首先是开放类型挖掘,基于事件检测得到的事件库、日志等数 据,我们挖掘出事件对应的类型并进行层次构建。在得到这样一个事件类型体系之后, 我们会针对事件类型进行相关资讯召回,再进行每个类型的角色挖掘。最后再进行人工校验。通过这种方式,我们在几十个领域中得到几千个事件类型,以及一万多的事 件角色。
5. 事件抽取
① 事件要素结构化抽取
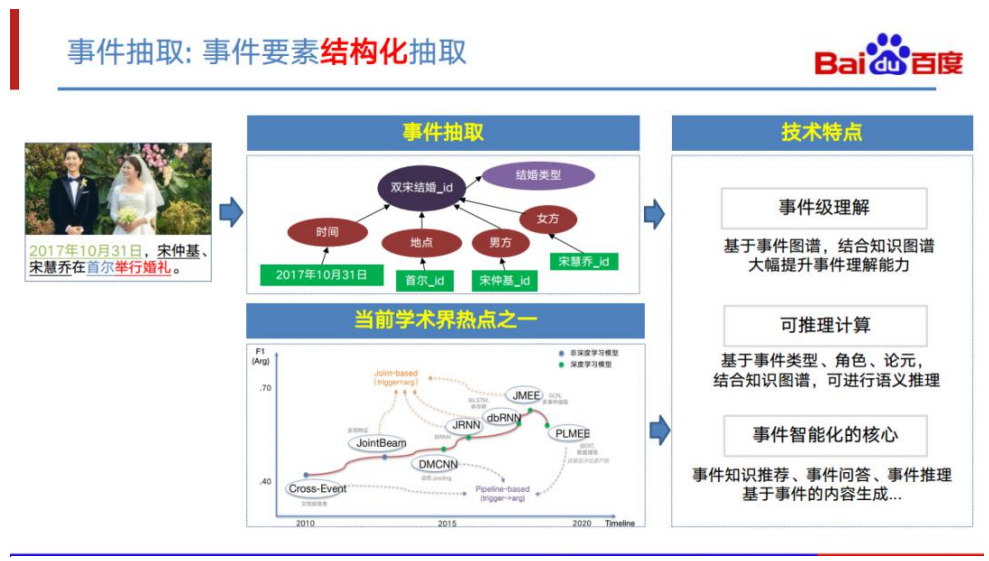 第三步是事件抽取的任务。事件抽取的目标是对事件的相关要素进行结构化的抽取。 还是以宋仲基、宋慧乔结婚为例,抽取的目标是,将这个事件抽取出来,并且能够识 别它是一个结婚的事件类型,并且根据结婚类型的角色,包括时间、地点、男方、女 方等,单独抽取出每个角色的具体的值。事件抽取的技术特点是: 事件抽取是事件级理解的基础。只有通过事件抽取,才能够将事件图谱和知识 图谱结合起来,提升事件理解能力; 事件抽取的结果可支持推理计算。基于事件类型、 角色、 论元,结合知识 图谱可进行语义推理。 事件抽取是事件智能化的核心。其可以支持推荐、问答、 推理、基于事件的 内容生成等不同的应用。 事件抽取是当前学术界的热点之一。近年来有很多优秀的事件抽取论文在自然语言处 理顶会、顶刊上发表。然而,事件抽取的技术难度依然是较大的,学术上效果还没有 达到直接可用的水平,目前在公开权威数据集 ACE2005 上论元分类任务只有 60% 左右的 F1。
第三步是事件抽取的任务。事件抽取的目标是对事件的相关要素进行结构化的抽取。 还是以宋仲基、宋慧乔结婚为例,抽取的目标是,将这个事件抽取出来,并且能够识 别它是一个结婚的事件类型,并且根据结婚类型的角色,包括时间、地点、男方、女 方等,单独抽取出每个角色的具体的值。事件抽取的技术特点是: 事件抽取是事件级理解的基础。只有通过事件抽取,才能够将事件图谱和知识 图谱结合起来,提升事件理解能力; 事件抽取的结果可支持推理计算。基于事件类型、 角色、 论元,结合知识 图谱可进行语义推理。 事件抽取是事件智能化的核心。其可以支持推荐、问答、 推理、基于事件的 内容生成等不同的应用。 事件抽取是当前学术界的热点之一。近年来有很多优秀的事件抽取论文在自然语言处 理顶会、顶刊上发表。然而,事件抽取的技术难度依然是较大的,学术上效果还没有 达到直接可用的水平,目前在公开权威数据集 ACE2005 上论元分类任务只有 60% 左右的 F1。
② 挑战与方案
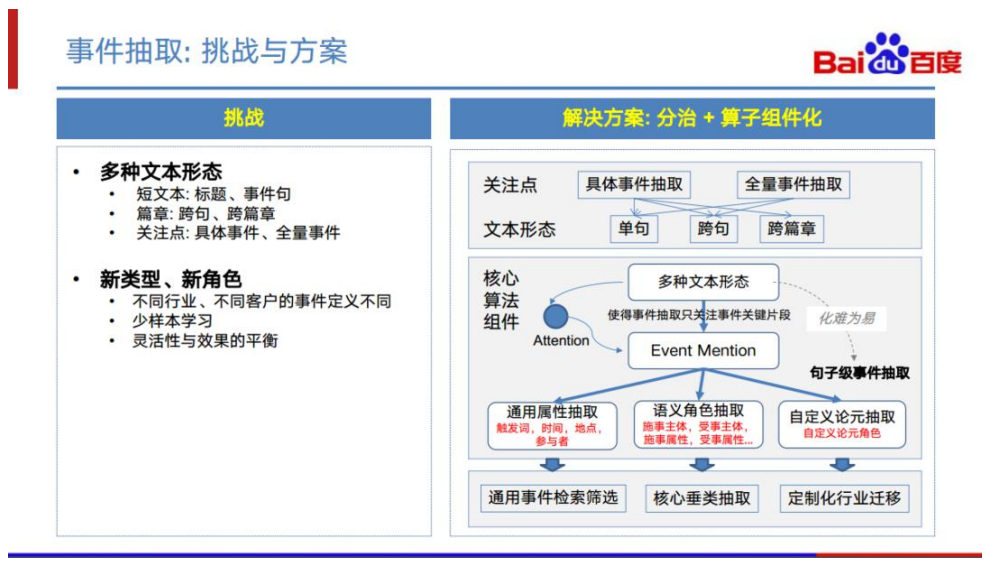 目前百度通过类型角色设计、前后处理、模型优化方面的努力,在特定场景下效果能 达到业务需求。但除了效果,事件抽取还有其他方面的挑战。 事件抽取必须面对多种多样的文本形态。事件抽取有时候需要从短文本中抽取, 如标题、事件句;有时候需要从篇章的角度进行抽取;有时候还需要跨篇章围 绕某事件进行抽取。 事件抽取需要具备灵活地根据角色抽取的能力。不同行业的场景常常存在不同 的事件类型、不同的事件角色的抽取需求,甚至同一个行业中,不同的客户对 事件类型或者事件角色定义也有可能是不同的。 我们整体的解决方案如右图。针对不同的关注点和文本形态,我们均挖掘出核心的事 件句。然后,基于这些事件句,针对不同场景使用不同的抽取技术进行抽取。目前我 们已具备的抽取技术包括通用属性抽取、语义角色抽取和自定义的论元抽取。
目前百度通过类型角色设计、前后处理、模型优化方面的努力,在特定场景下效果能 达到业务需求。但除了效果,事件抽取还有其他方面的挑战。 事件抽取必须面对多种多样的文本形态。事件抽取有时候需要从短文本中抽取, 如标题、事件句;有时候需要从篇章的角度进行抽取;有时候还需要跨篇章围 绕某事件进行抽取。 事件抽取需要具备灵活地根据角色抽取的能力。不同行业的场景常常存在不同 的事件类型、不同的事件角色的抽取需求,甚至同一个行业中,不同的客户对 事件类型或者事件角色定义也有可能是不同的。 我们整体的解决方案如右图。针对不同的关注点和文本形态,我们均挖掘出核心的事 件句。然后,基于这些事件句,针对不同场景使用不同的抽取技术进行抽取。目前我 们已具备的抽取技术包括通用属性抽取、语义角色抽取和自定义的论元抽取。
③ 通用属性抽取
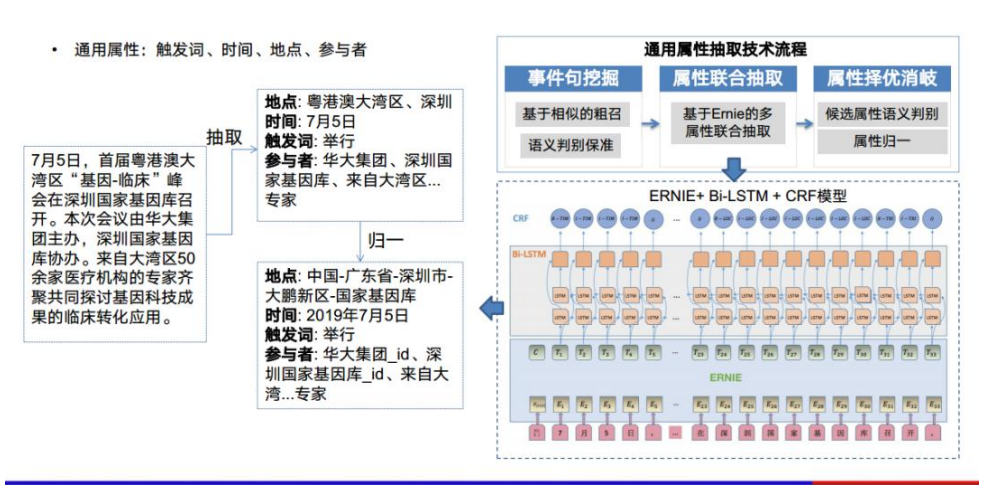
通用属性抽取的目的是抽取触发词、时间,地点、参与者等通用的事件角色。由于技 术是比较通用的,我们采取的是一个多属性联合抽取的模型。这里的 ERNIE 是百度 提出的一个预训练语言模型,在这基础上再加上 Bi-LSTM+CRF,同时抽取多个属性。 如图所示,该流程是先进行一次事件句的识别,找到关于某个事件的句子。然后,再 对这个句子进行多属性联合抽取,并对抽取的结果进行归一。地点归一到国家、省市 区县等,时间进行规范化、参与者实体化等等。
④ 自定义论元抽取
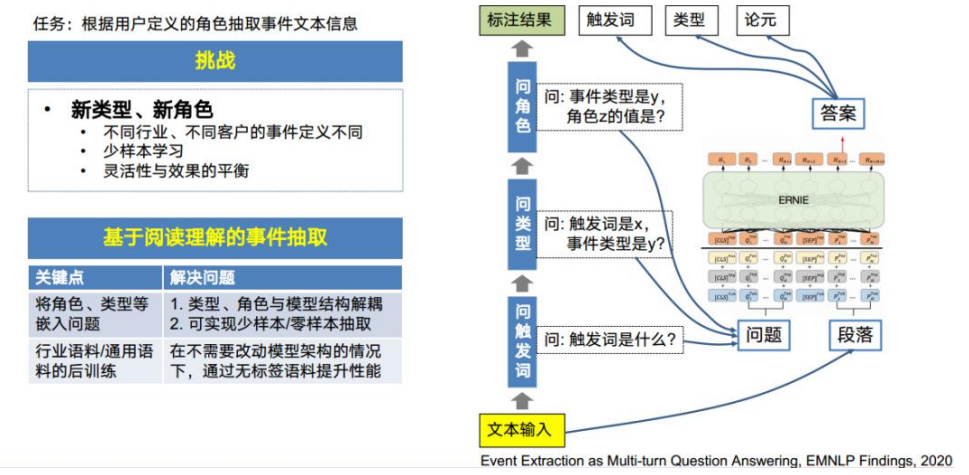
自定义论元抽取要解决的问题就是如何根据用户定义的角色少样本甚至零样本地进 行事件抽取。我们的方案是基于阅读理解问答的事件抽取模型。 我们把整个事件抽取的流程分成三轮问答: 第一轮,问触发词,抽取出输入事件句的触发词是什么。 第二轮,问整个输入句子的事件类型。 第三轮,是根据第二步抽取的结果,对该事件类型对应的每个角色进行问答抽 取。 这个方案中,角色、事件类型这些本来跟模型耦合的东西都解耦了,新的角色和事件 类型只需要把它们放到问题中就可以抽取,从而实现少样本、甚至零样本的抽取。相 关研究成果已被 EMNLP Findings,2020 收录。
⑤ 语义角色抽取
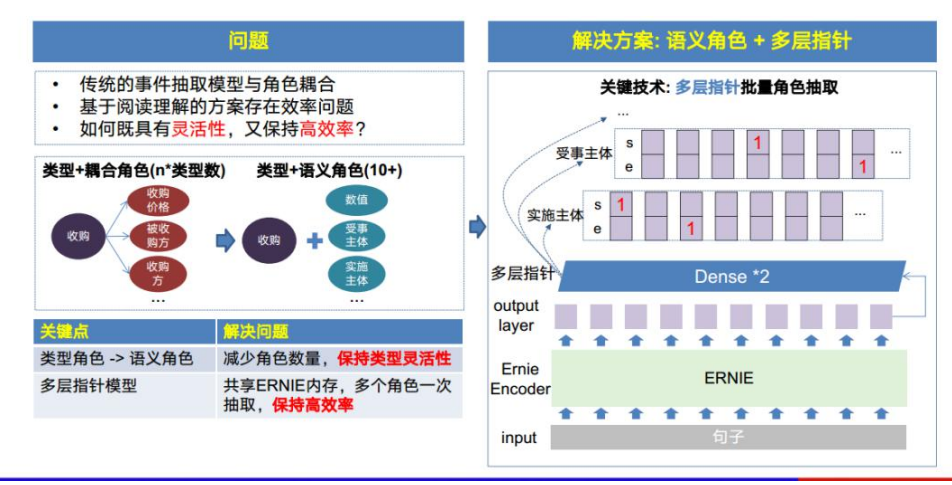
刚才讲到了两种事件抽取的方式,一种是通用属性抽取,一种是基于问答的论元抽取。 通用属性抽取的问题是无法灵活的泛化。阅读理解方案的问题则是效率,因为我们需 要对每一个角色都进行单独提问抽取。有没有一种方法可以既具灵活性又具备高效 率?我们对这个问题提出了多种不同的方案,其中一种方案是:语义角色抽取。 从左边中间这幅图我们可以看到常见的事件类型跟它的角色是存在一定的关联关系 的,但实际上也可以把它们解耦成一个类型和一系列的语义角色的。例如,“收购” 类型和角色“收购价格”、“被收购方”和“收购方”是耦合的。如果把所有如“收 购价格”、“被收购方”、“收购方”这样的类型角色转化为如“数值”、“受事主 体”、“实施主体”这样的与类型解耦的语义角色,我们整体的角色数量就可以就可 以从 n*类型数这一数量级,降低到只有十几个语义角色的量级。 在这个基础之上我们还可以通过多层指针结构对不同的语义角色同时进行抽取。如右 图所示,整个句子只需要一次进入预训练语言模型后,再进入多层指针网络就可以同 时抽取所有的角色。 这样既保持了整体的灵活性也保持了抽取的高效率。
6. 关系挖掘
 事件之间存在多种关系。我们目前定义了 4 种关系,包括从属关系、共指关系、时序 关系和因果关系。由于时间的关系,我本次只分享因果关系。
因果关系:
事件之间存在多种关系。我们目前定义了 4 种关系,包括从属关系、共指关系、时序 关系和因果关系。由于时间的关系,我本次只分享因果关系。
因果关系:

因果关系的挖掘存在诸多挑战: 第一个挑战是因果的主观性。对哲学有了解的朋友可能会知道,哲学家大卫·休 谟提过这么一个命题——“明天的太阳未必会升起”。意思是逻辑上,人类是 无法根据过去太阳一直都这么升起的经验,来推理出未来太阳也这么升起。也 就是说,因果关系不是绝对的、客观的,它只是是人类对我们过去的经验的一 种主观总结。 第二个挑战是因果的复杂性。一个事情可能是一因多果,也可能是一果多因或 者是多因多果。要完整地将事件的所有因果抽取出来难度较大。 下面是一些我们解决这些问题的具体思路: 首先,因果关系在客观上是非常难判定的,不同人对因果有不同理解。因此, 我们把因果关系当作观点来看待,直接绕过这个正确性的问题。通过因果的出 现次数、来源的权威性等方面来评价抽取出的因果的质量。 第二,将因果关系作为序列标注问题,同时去标注多因多果,部分解决上面提 到的复杂的、多因多果问题。 第三,对存在因果稀疏的问题。虽然在不同的语料中存在的因果关系是比较少 的,但通过归一的方法我们可以将单独存在于多个不同地方的因果表达聚合到 同一个网络图谱中,从而形成一个完整的因果图谱。 具体而言,我们的方案如右图所示。通过因果事件的挖掘,我们可以从不同的篇章当 中挖掘出大量的因果关系。比如,“生猪存栏环比回升”导致了“猪肉价格明显回落” 是一个因果。然后,再对这些抽取出来的因果 Pair 中的每个事件节点再进行归一, 将不同篇章中描述的相同事件归一在一起。归一结束后,我们就可以得到一个能支持 多步因果的因果图谱。我们目前已经形成一个节点正确率 90+%,节点数、关系数达 到百万量级的因果图谱。
7. 事理图谱
 此基础上我们就可以进行因果推理了。比如,想知道某个事情是由什么原因导致的? 它可能会有什么后果?我们只需要在因果图谱中先定位到这个节点,然后就可以在图 谱上面进行基于拓扑的推理。
此基础上我们就可以进行因果推理了。比如,想知道某个事情是由什么原因导致的? 它可能会有什么后果?我们只需要在因果图谱中先定位到这个节点,然后就可以在图 谱上面进行基于拓扑的推理。
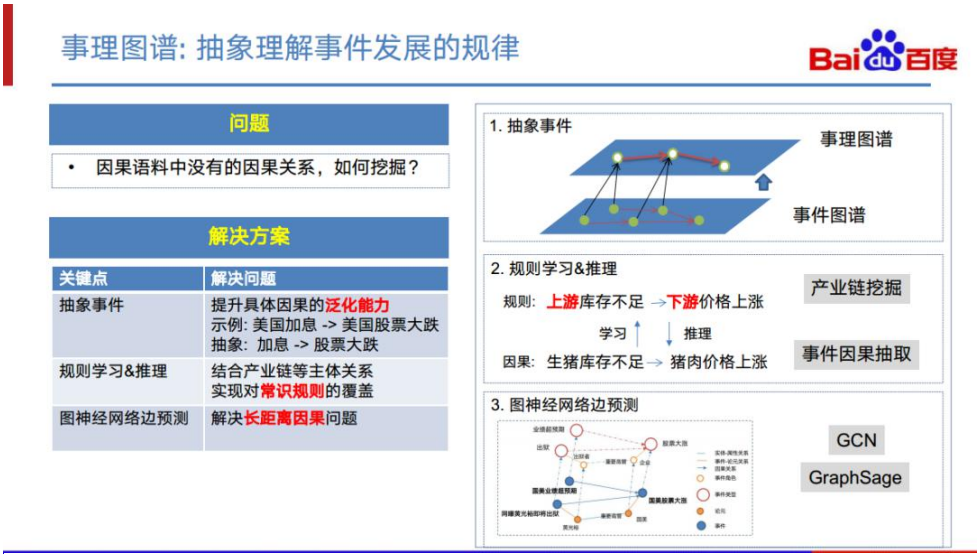
问题来了,如果说我们需要进行推理的事件在因果语料中不存在,那我们应该怎么样 进行推理和挖掘呢?目前我们正在尝试的 3 个思路如下: 基于事理的推理。我们认为的事件是客观世界中发生的某个具体事件,抽象事 件则是对一类事件的抽象,而事理则是这些抽象事件的因果规律。比如,“某 一天美国加息”,就是美国在具体某一天的加息,而“美国加息”事件则是对 这一类事件的抽象。由于“美国加息”这类事件常常会导致“美元的汇率上升” 这样的抽象事件发生,那么,新的一次美国加息事件,也非常有可能导致汇率 上升。这种抽象后的事件规律,我们会把它放在事理图谱层次,来支持泛化的 推理。 基于规则的推理。举个例子,“生猪库存不足”会导致“猪肉价格上涨”。在 这里面,两个主体“生猪”和“猪肉”,其实是存在产业链关系的。“生猪” 是上游,“猪肉”是下游。通过观察一系列的类似的因果,我们可以挖掘出这 样一个规则:上游的库存不足,可能会导致下游的价格上涨。那么面对一种新 事件的时候,比如说钢铁库存不足,我们就可以推理预测下游一些钢铁产品的 价格可能会上涨。 基于图神经网络的因果的预测。上面两种方法中,本质上都可以认为是一种简 单的规则方法,当事件较为复杂,或者需要多步推理时,上面的方法就不能适 用。例如,“网曝黄光裕即将出狱”可能导致了“国美”股票大涨。这中间存 在了多步推理关系,首先是“黄光裕”出狱的这个事件的“出狱者”是“黄光 裕”,而“黄光裕”是“国美”的一个重要高管,然后 “国美”对应的股票 出现“大涨”事件。这是一个多步推理的过程,比较难以通过事件抽象或是规 则进行建模。我们正在尝试将每一个事件节点都放到整个图当中去进行考虑。 通过图的方式对这里面的事件节点进行边的预测。
03 事件图谱应用
上面我已经讲了事件图谱的检测、表示、抽取以及因果关系,下面我将介绍事件图谱 在百度以及行业中的具体应用:

目前百度事件图谱的相关应用主要有这四块。第一块是热点发现,第二块是事件脉络, 第三块是资源关联,第四块是因果推理。
1. 多维度热点事件发现

在热点发现这一块,我们能够做到分钟级的热点发现。对于行业热点、地域热点等中 长尾事件也可以做到分钟级的发现,因此我们可以支持很多对中长尾、小事件敏感的 应用场景。目前我们的事件检测已能够支持二十多个行业、三百多个省市的分钟级的 热点发现,并在人民网,齐鲁网等数十家媒介机构中落地。
2. 事件脉络

其次是事件脉络。通过事件图谱的整个事件的关联关系,我们在搜索上上线了热点事 件脉络,可以将热点事件的前因后果进行关联,并以脉络的形式呈现给用户,大大提 升了用户了解热点前因后果的效率。在疫情中,我们也通过事件脉络支持了疫情相关 的事件脉络的查询。目前脉络相关的产品也支持了百度智能创作平台、事件脉络视频 等众多应用。
3. 资源关联
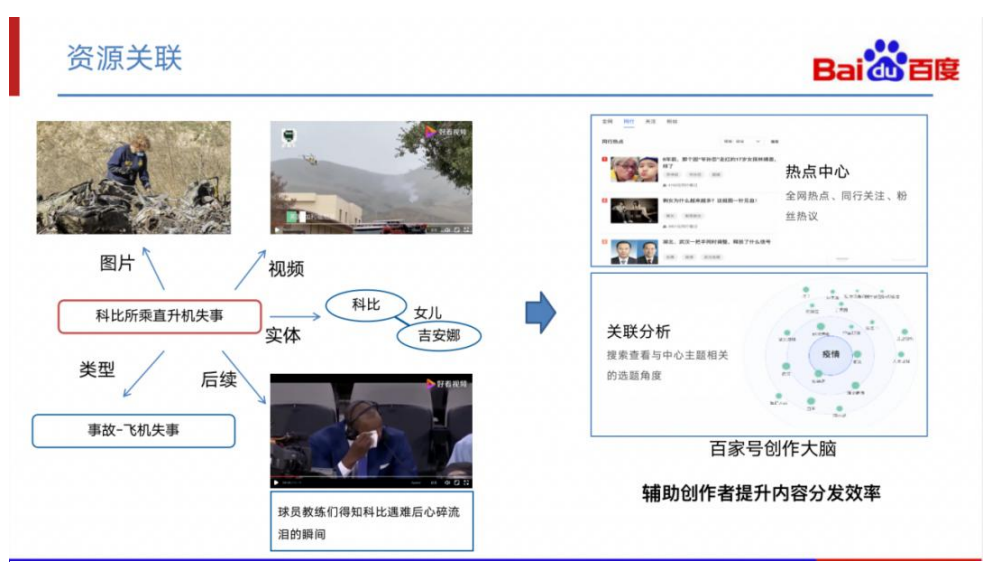 第三块是资源关联。事件图谱围绕事件将相关的资源,如资讯、图片、视频等进行关 联。目前我们通过这样的技术在“百家号的创作大脑”上面进行了应用,通过事件中 心资源组织,辅助作者的内容生产分发效率大幅提升。
第三块是资源关联。事件图谱围绕事件将相关的资源,如资讯、图片、视频等进行关 联。目前我们通过这样的技术在“百家号的创作大脑”上面进行了应用,通过事件中 心资源组织,辅助作者的内容生产分发效率大幅提升。
4. 因果推理
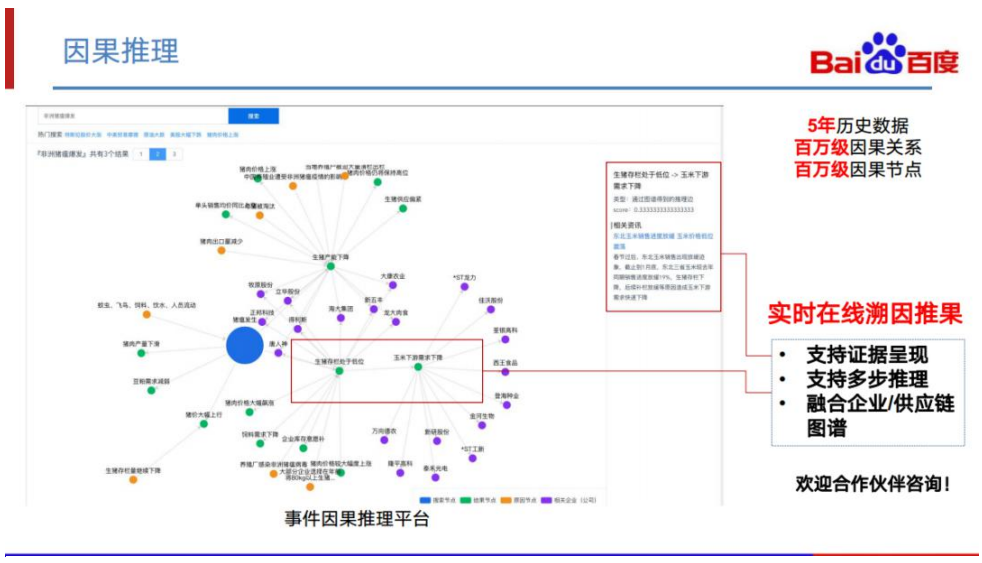 最后一块是因果推理。目前,我们在金融领域做了一些因果推理的尝试。我们将 5 年 历史数据的相关因果进行挖掘和提取,构成了一个因果图谱。该图谱目前的规模接近 两百万节点与关系。我们能够进行在线、实时的溯因推理。支持推理的证据呈现,也 支持多步推理。同时还可以融合企业与供应链图谱,进行上下游事件推理。以 “非 洲猪瘟爆发”为例,该事件爆发会导致 “生猪存栏处于低位”,同时也会导致下游
“玉米需求”下降,最终影响到与“玉米”行业相关的公司。目前在这个方向上,我 们还处于探索阶段,非常欢迎金融圈感兴趣的朋友们跟我们一起合作&探讨。
最后一块是因果推理。目前,我们在金融领域做了一些因果推理的尝试。我们将 5 年 历史数据的相关因果进行挖掘和提取,构成了一个因果图谱。该图谱目前的规模接近 两百万节点与关系。我们能够进行在线、实时的溯因推理。支持推理的证据呈现,也 支持多步推理。同时还可以融合企业与供应链图谱,进行上下游事件推理。以 “非 洲猪瘟爆发”为例,该事件爆发会导致 “生猪存栏处于低位”,同时也会导致下游
“玉米需求”下降,最终影响到与“玉米”行业相关的公司。目前在这个方向上,我 们还处于探索阶段,非常欢迎金融圈感兴趣的朋友们跟我们一起合作&探讨。
5. 事件抽取数据集及评测任务
 在推动学界、业界事件相关技术发展方面,我们在 2020 语言与智能技术竞赛中发布 了目前最大的中文事件抽取数据集——DuEE,并吸引了一千多支团队报名。该数据 集目前已经对外开源,在千言项目当中可以进行公开下载,同时我们也提供了一个公 开的测评榜单,欢迎大家打榜参与,共同推动技术的发展。
在推动学界、业界事件相关技术发展方面,我们在 2020 语言与智能技术竞赛中发布 了目前最大的中文事件抽取数据集——DuEE,并吸引了一千多支团队报名。该数据 集目前已经对外开源,在千言项目当中可以进行公开下载,同时我们也提供了一个公 开的测评榜单,欢迎大家打榜参与,共同推动技术的发展。
04 总结与展望
1. 总结
在本次分享中,我首先对事件图谱的价值进行了分享,包括认知方面的价值以及应用 方面的价值。然后介绍了事件图谱的构建技术,包括检测、表示、抽取以及因果关系。 同时也介绍了我们在事理图谱上的一些想法。最后分享了事件图谱的相关应用示例, 包括热点发现、事件脉络、资源聚合以及因果推理等。
2. 展望
在未来,百度事件图谱的发展方向主要包括三个方面: 在技术方面,我们会进一步完善事件的构建能力,包括抽取、事件关系与事理。 在应用方面,我们还会进一步强化应用方面的能力,包括基于事件的理解、资 源组织和辅助决策等能力。 在行业化方面,我们会面向行业进行进一步的深入探索,努力通过事件图谱的 技术赋能行业。