深度学习的世界不仅仅是dense层。您可以向模型添加数十种图层。(尝试浏览 [Keras]文档以获取示例!)有些类似于dense层并定义神经元之间的连接,而有些则可以进行其他类型的预处理或转换。 在本文章中,我们将了解两种特殊层,它们本身不包含任何神经元,但会添加一些功能,有时可以以各种方式使模型受益。两者都常用于现代模型结构中。
Dropout
其中第一个是“dropout 层”,它可以帮助纠正过拟合。
在上一篇文章中,我们讨论了网络学习训练数据中的虚假模式如何导致过度拟合。为了识别这些虚假模式,网络通常会依赖于非常特定的权重组合,一种权重的“阴谋”。但是,它们往往很脆弱:删除一个,阴谋就会瓦解。
这就是 dropout 背后的想法。为了打破这些阴谋,我们在训练的每一步随机丢弃层输入单元的一部分,使网络更难学习训练数据中的那些虚假模式。相反,它必须搜索广泛的、通用的模式,其权重模式往往更加稳健。
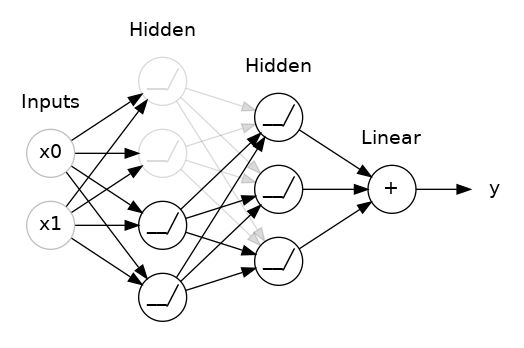
在这里,在两个隐藏层之间添加了 50% 的 dropout。 我们也可以将 dropout 看做是构造一种网络集成。不再是由一个大网络给出预测结果,而是由一个委员会(由较小网络组成的)做出。委员会中的个人往往会犯不同类型的错误,但同时又是对的,这使整个委员会比任何人都好。 (如果您熟悉作为决策树集合的随机森林,那么这是相同的想法。)
Adding Dropout
在 Keras 中,dropout rate 参数 rate 定义了要关闭的输入单元的百分比。将 Dropout 层放在要应用 dropout 的层之前:
keras.Sequential([
# ...
layers.Dropout(rate=0.3), # apply 30% dropout to the next layer
layers.Dense(16),
# ...
])
Batch Normalization
下一个比较特殊的层是执“batch normalization”(或“batchnorm”),这有助于纠正缓慢或不稳定的训练。 对于神经网络,通常是将所有数据缩放到一个共同的尺度上,可以使用 scikit-learn 中的 StandardScaler 或 MinMaxScaler 之类的方法。 现在,如果在数据进入网络之前对其进行规范化是好的,也许在网络内部进行规范化会更好!事实上,我们有一种特殊的层可以做到这一点,即batch normalization layer(批量归一化层)。batch normalization layer会在每个批次(batch)进来时查看它,首先用它自己的均值和标准差对批次进行归一化,然后还使用两个可训练的重新缩放参数将数据放在一个新的尺度上。实际上,Batchnorm 对其输入进行了一种协调的重新缩放。 大多数情况下,batchnorm 被看作是优化过程的辅助工具(尽管它有时也有助于预测性能)。具有batchnorm的模型往往需要更少的 epoch 来完成训练。此外,batchnorm 还可以解决可能导致训练“卡住”的各种问题。考虑为模型添加批量归一化,尤其是当您在训练过程中遇到问题时。
Adding Batch Normalization
似乎batch normalization layer几乎可以用于网络中的任何一点。你可以把它放在一层之后......
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),
...或在层与其激活函数之间:
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),
如果将其添加为网络的第一层,它可以充当一种自适应预处理器,替代 Sci-Kit Learn 的 StandardScaler 之类的东西。
练习
在本练习中,我们将为上一节(4-过拟合与欠拟合)中的 Spotify 模型添加 dropout,并了解批量归一化如何让您在困难的数据集上成功训练模型。
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from sklearn.model_selection import GroupShuffleSplit
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import callbacks
spotify = pd.read_csv('datasets/spotify.csv')
X = spotify.copy().dropna()
y = X.pop('track_popularity')
artists = X['track_artist']
features_num = ['danceability', 'energy', 'key', 'loudness', 'mode',
'speechiness', 'acousticness', 'instrumentalness',
'liveness', 'valence', 'tempo', 'duration_ms']
features_cat = ['playlist_genre']
preprocessor = make_column_transformer(
(StandardScaler(), features_num),
(OneHotEncoder(), features_cat),
)
def group_split(X, y, group, train_size=0.75):
splitter = GroupShuffleSplit(train_size=train_size)
train, test = next(splitter.split(X, y, groups=group))
return (X.iloc[train], X.iloc[test], y.iloc[train], y.iloc[test])
X_train, X_valid, y_train, y_valid = group_split(X, y, artists)
X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
y_train = y_train / 100
y_valid = y_valid / 100
input_shape = [X_train.shape[1]]
print("Input shape: {}".format(input_shape))
这是练习 4 中的最后一个模型。添加两个 dropout 层,一个在具有 128 个单元的 Dense 层之后,一个在具有 64 个单元的 Dense 层之后。将两者的辍学率设置为 0.3。
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.Dropout(rate=0.3),
layers.Dense(64, activation='relu'),
layers.Dropout(rate=0.3),
layers.Dense(1)
])
现在运行下一个单元格来训练模型,看看添加 dropout 的效果。
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=50,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()))
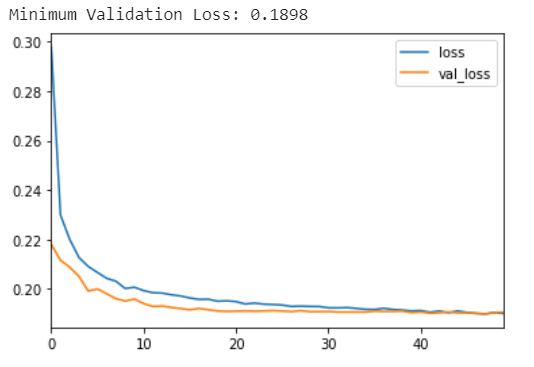
回忆一下在上一节的练习中,这个模型大致在epoch5左右就开始过拟合了。这次添加 dropout 似乎有助于防止过度拟合? 从学习曲线中,您可以看到即使训练损失继续减少,验证损失仍保持在恒定最小值附近。所以我们可以看到,这次添加 dropout 确实防止了过拟合。此外,通过使网络更难拟合虚假模式,dropout 可能会鼓励网络寻找更多的真实模式,也可能会改善一些验证损失)。 现在,我们将切换主题来探讨batch normalization如何解决训练中的问题。 加载我们之前用过的混凝土数据集(Concrete dataset.)。这次我们不做任何标准化。这将使批量归一化的效果更加明显。
import pandas as pd
concrete = pd.read_csv('datasets/concrete.csv')
df = concrete.copy()
df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)
X_train = df_train.drop('CompressiveStrength', axis=1)
X_valid = df_valid.drop('CompressiveStrength', axis=1)
y_train = df_train['CompressiveStrength']
y_valid = df_valid['CompressiveStrength']
input_shape = [X_train.shape[1]]
接着写
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=input_shape),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='sgd', # SGD is more sensitive to differences of scale
loss='mae',
metrics=['mae'],
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=64,
epochs=100,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))
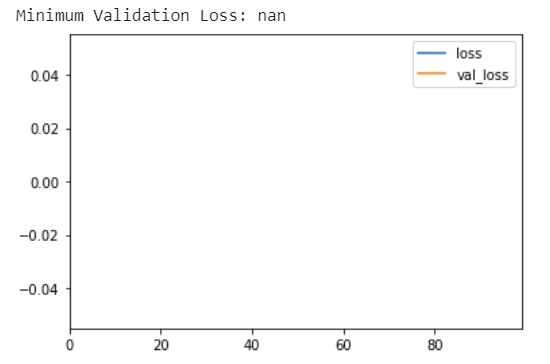
history_df.loc[0:, ['loss', 'val_loss']]
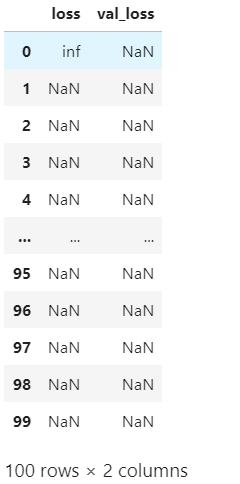
你最终得到了一张空白图表吗?尝试在此数据集上训练此网络通常会失败。即使它确实收敛(由于幸运的权重初始化),它也倾向于收敛到一个非常大的数字。 批量标准化可以帮助纠正这样的问题。 添加四个 BatchNormalization 层,在每个dense层之前一层。
model = keras.Sequential([
layers.BatchNormalization(input_shape=input_shape),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(1),
])
接下来是模型训练
model.compile(
optimizer='sgd',
loss='mae',
metrics=['mae'],
)
EPOCHS = 100
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=64,
epochs=EPOCHS,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))
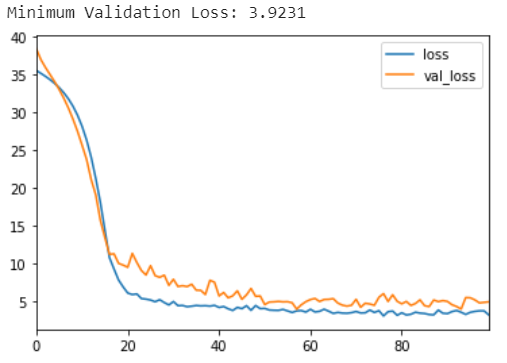
添加批量标准化有帮助吗? 您可以看到,在第一次尝试时,添加批量标准化是一个很大的改进!通过在数据通过网络时自适应地缩放数据,批量归一化可以让您在困难的数据集上训练模型。