长短期记忆网络
1.目录
2.长短期记忆网络:
- 忘记门:将值朝0减少
- 输入门:决定是不是忽略掉输入数据
- 输出门:决定是不是使用隐状态
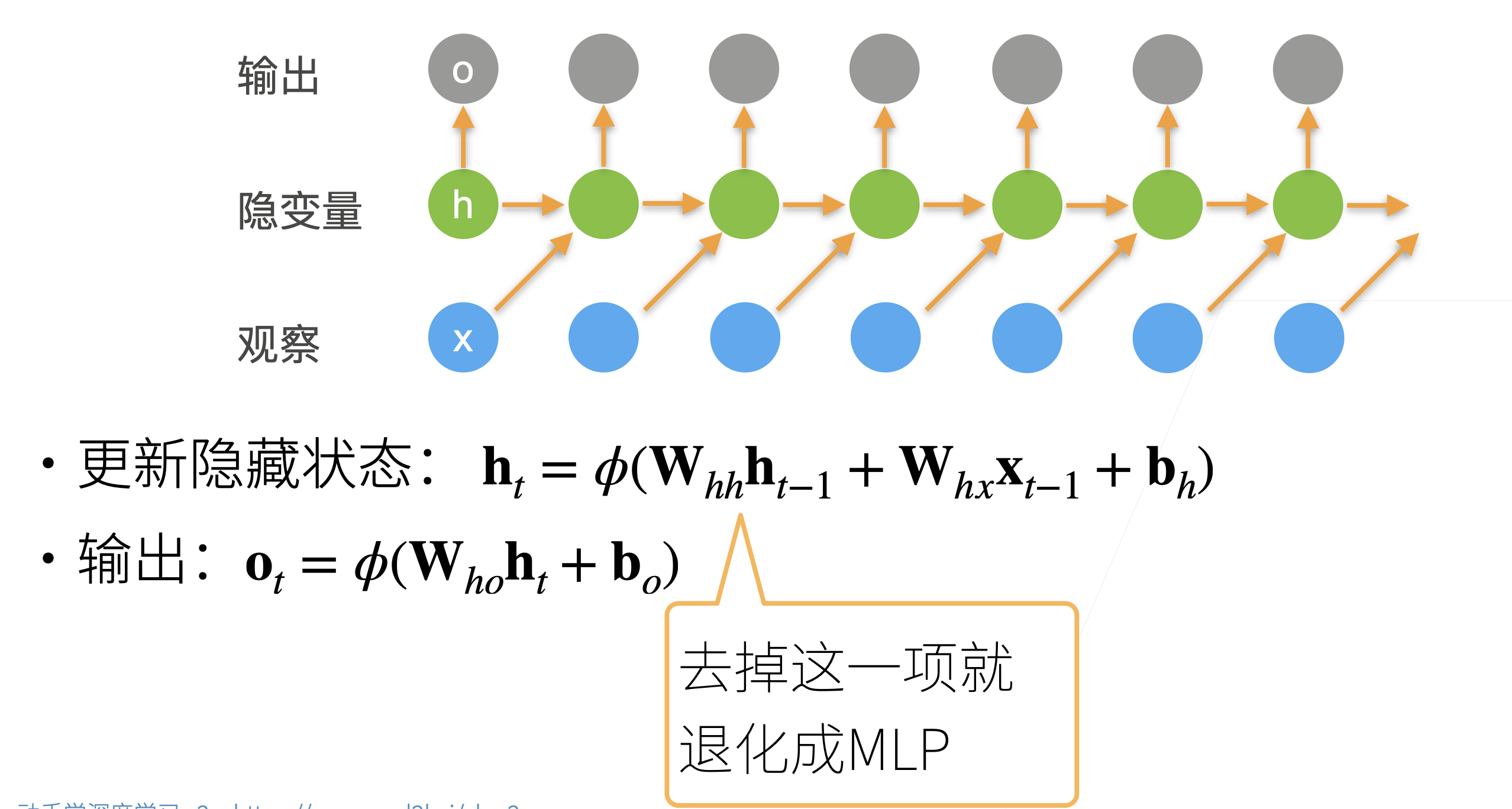
可以说,长短期记忆网络的设计灵感来自于计算机的逻辑门。 长短期记忆网络引入了记忆元(memory cell),或简称为单元(cell)。 有些文献认为记忆元是隐状态的一种特殊类型, 它们与隐状态具有相同的形状,其设计目的是用于记录附加的信息。 为了控制记忆元,我们需要许多门。 其中一个门用来从单元中输出条目,我们将其称为输出门(output gate)。 另外一个门用来决定何时将数据读入单元,我们将其称为输入门(input gate)。 我们还需要一种机制来



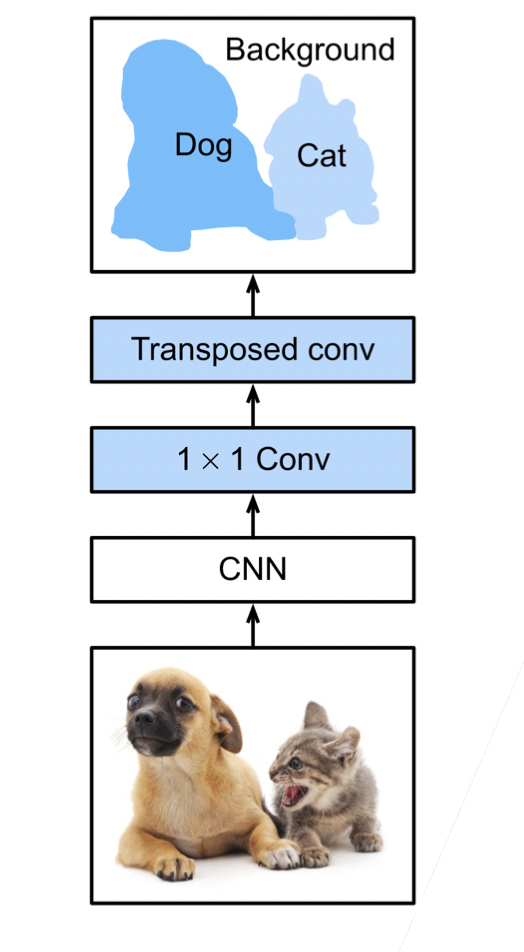
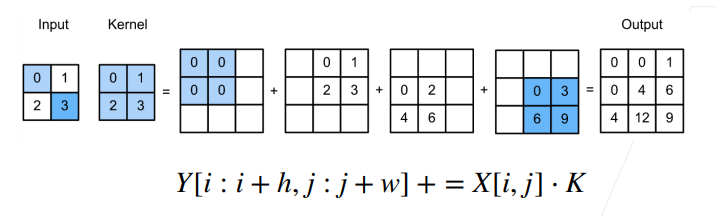 如图所示,input里的每个元素和kernel相乘,最后把对应位置相加,相当于卷积的逆变换
如图所示,input里的每个元素和kernel相乘,最后把对应位置相加,相当于卷积的逆变换