Recurrent Neural Networks
如果你想进入机器学习领域,循环神经网络是一种很重要的技术,需要理解。如果你使用智能手机或经常上网,你很有可能接触过利用 RNN 的应用程序。循环神经网络用于语音识别、语言翻译、股票预测;它甚至用于图像识别以描述图片中的内容。
Sequence Data
RNN 是擅长对序列数据建模的神经网络。为了理解这句话的含义,我们来看一个小实验。假设你拍摄了一个及时移动的球的静止快照。
 图1
假设你想预测球移动的方向。那么只有你在屏幕上看到的信息,你会怎么做?你可以猜测一下,但你想出的任何答案都是随机猜测。如果不知道球的位置,就没有足够的数据来预测球的去向。
如果我们连续记录球位置的快照,你将有足够的信息来做出更好的预测。
图1
假设你想预测球移动的方向。那么只有你在屏幕上看到的信息,你会怎么做?你可以猜测一下,但你想出的任何答案都是随机猜测。如果不知道球的位置,就没有足够的数据来预测球的去向。
如果我们连续记录球位置的快照,你将有足够的信息来做出更好的预测。
 图2
这就是一个序列,一个事物跟随另一个事物的特定顺序。有了这些信息,现在可以看到球正在向右移动。
序列数据(Sequence data )有多种形式。音频是一个自然序列。我们可以将音频频谱图切成块,然后将其输入 RNN。
图2
这就是一个序列,一个事物跟随另一个事物的特定顺序。有了这些信息,现在可以看到球正在向右移动。
序列数据(Sequence data )有多种形式。音频是一个自然序列。我们可以将音频频谱图切成块,然后将其输入 RNN。
 图3
文本是另一种形式的序列。您可以将文本分解为字符序列或单词序列。
图3
文本是另一种形式的序列。您可以将文本分解为字符序列或单词序列。
Sequential Memory
RNN 擅长处理序列数据以进行预测。但是是如何做的呢?
他们通过一个我喜欢称之为顺序内存的概念来做到这一点。为了对顺序内存的含义有一个很好的理解,我想请你说出你脑海中的英文字母表。
 图4
你很容易就说对。如果你学过这个特定的顺序,你能很快想起来这个字母表。
但是如果现在试着倒着念字母表呢
图4
你很容易就说对。如果你学过这个特定的顺序,你能很快想起来这个字母表。
但是如果现在试着倒着念字母表呢
 图5
我敢打赌这要困难得多。除非你以前练习过这个特定的序列,否则你可能会很难快速说出。
有一个有趣的例子,我们从字母 F 开始。
图5
我敢打赌这要困难得多。除非你以前练习过这个特定的序列,否则你可能会很难快速说出。
有一个有趣的例子,我们从字母 F 开始。
 图6
一开始,你会在前几个字母上挣扎,但是当你的大脑掌握了模式后,剩下的就会自然而然地说出来了。
这样做有些困难是非常合乎逻辑的。我们学习的字母表是一个序列,顺序记忆是一种让大脑更容易识别顺序模式的机制。
图6
一开始,你会在前几个字母上挣扎,但是当你的大脑掌握了模式后,剩下的就会自然而然地说出来了。
这样做有些困难是非常合乎逻辑的。我们学习的字母表是一个序列,顺序记忆是一种让大脑更容易识别顺序模式的机制。
Recurrent Neural Networks
RNN 有这个抽象的顺序记忆概念,但是 RNN 到底是如何实现这个概念的呢?首先,让我们看看传统的神经网络,也称为前馈神经网络。它有输入层、隐藏层和输出层。
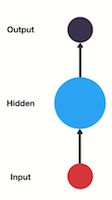 图7
图7
Vanishing Gradient
我们如何让前馈神经网络能够使用以前的信息来影响以后的信息?如果我们在神经网络中添加一个可以向前传递先验信息的循环会怎样?
 图8
这本质上就是循环神经网络所做的。 RNN 具有循环机制,可充当高速公路以允许信息从一个步骤流到下一个步骤。
图8
这本质上就是循环神经网络所做的。 RNN 具有循环机制,可充当高速公路以允许信息从一个步骤流到下一个步骤。
 图9
这种信息是隐藏状态,它是先前输入的一种表示。让我们通过一个 RNN 用例来更好地理解它是如何工作的。
假设我们想构建一个聊天机器人。它们现在很受欢迎。假设聊天机器人可以从用户输入的文本中对意图进行分类。
图9
这种信息是隐藏状态,它是先前输入的一种表示。让我们通过一个 RNN 用例来更好地理解它是如何工作的。
假设我们想构建一个聊天机器人。它们现在很受欢迎。假设聊天机器人可以从用户输入的文本中对意图进行分类。
 图10
为了解决这个问题。首先,我们将使用 RNN 对文本序列进行编码。然后,我们将把 RNN 的输出内容,输入到一个前馈神经网络中,该网络将对意图进行分类。
举个例子,用户输入"现在几点了"这句话,首先,我们将句子分解为单个单词。 RNN 是按顺序工作的,所以我们一次输入一个词。
图10
为了解决这个问题。首先,我们将使用 RNN 对文本序列进行编码。然后,我们将把 RNN 的输出内容,输入到一个前馈神经网络中,该网络将对意图进行分类。
举个例子,用户输入"现在几点了"这句话,首先,我们将句子分解为单个单词。 RNN 是按顺序工作的,所以我们一次输入一个词。
 图11
第一步是将“What”输入 RNN。 RNN 对“What”进行编码并产生输出。
图11
第一步是将“What”输入 RNN。 RNN 对“What”进行编码并产生输出。
 图12
对于下一步,我们输入“time”一词和上一步中的隐藏状态。 RNN 现在有关于“What”和“time”这两个词的信息。
图12
对于下一步,我们输入“time”一词和上一步中的隐藏状态。 RNN 现在有关于“What”和“time”这两个词的信息。
 图13
我们重复这个过程,直到最后一步。你可以通过最后一步看到,RNN 已经对前面步骤中所有单词的信息进行了编码。
图13
我们重复这个过程,直到最后一步。你可以通过最后一步看到,RNN 已经对前面步骤中所有单词的信息进行了编码。
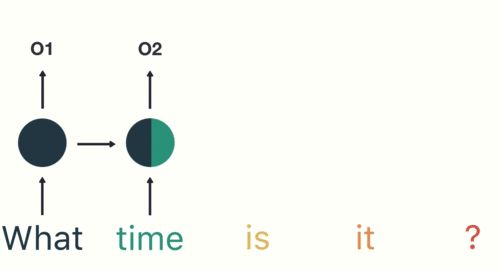 图14
由于最终的输出是根据序列的其余部分创建的,我们能够获取最终输出并将其传递给前馈层以对意图进行分类。
图14
由于最终的输出是根据序列的其余部分创建的,我们能够获取最终输出并将其传递给前馈层以对意图进行分类。
 图15
图15
Types of recurrent neural networks
前馈神经网络将一个输入映射到一个输出,而 RNN 可以映射一对多、多对多(翻译)和多对一(对语音进行分类)。我们来简单看下有哪些类型:
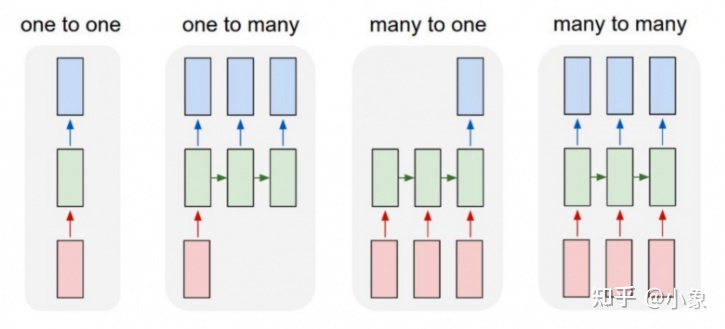 图16
- one to one: 是最基本和最传统的神经网络类型,为单个输入提供单个输出
- one to many: 适用于为单个输入提供多个输出的情况。一个基本示例是音乐生成。在音乐生成模型中,RNN 模型用于从单个音符(单个输入)生成音乐作品(多个输出)。
- many to one: 该架构通常被视为情感分析模型的常见示例。顾名思义,当需要多个输入来提供单个输出时,使用这种模型。以 Twitter 情感分析模型为例。在该模型中,文本输入(单词作为多个输入)给出其固定的情绪(单个输出)。另一个例子可能是电影评级模型,该模型将评论文本作为输入,为电影提供范围从 1 到 5 的评级。
- many to many: 多对多 RNN 架构接受多个输入并给出多个输出,但多对多模型可以是两种类型,1.输入和输出层具有相同大小的情况。这也可以理解为每一个输入都有一个输出,在Named-entity Recognition(命名实体识别)中经常用到。2.输入和输出层大小不同的模型,这种 RNN 架构最常见的应用是机器翻译。例如,“我爱你”,英语中的这 3 个神奇词语在西班牙语中只翻译成 2 个,“te amo”。所以应用这种架构,机器翻译模型能够返回比输入字符串更多或更少的单词。
你可能已经注意到隐藏状态中颜色的奇怪分布。这是为了说明 RNN 被称为短期记忆的问题。
图16
- one to one: 是最基本和最传统的神经网络类型,为单个输入提供单个输出
- one to many: 适用于为单个输入提供多个输出的情况。一个基本示例是音乐生成。在音乐生成模型中,RNN 模型用于从单个音符(单个输入)生成音乐作品(多个输出)。
- many to one: 该架构通常被视为情感分析模型的常见示例。顾名思义,当需要多个输入来提供单个输出时,使用这种模型。以 Twitter 情感分析模型为例。在该模型中,文本输入(单词作为多个输入)给出其固定的情绪(单个输出)。另一个例子可能是电影评级模型,该模型将评论文本作为输入,为电影提供范围从 1 到 5 的评级。
- many to many: 多对多 RNN 架构接受多个输入并给出多个输出,但多对多模型可以是两种类型,1.输入和输出层具有相同大小的情况。这也可以理解为每一个输入都有一个输出,在Named-entity Recognition(命名实体识别)中经常用到。2.输入和输出层大小不同的模型,这种 RNN 架构最常见的应用是机器翻译。例如,“我爱你”,英语中的这 3 个神奇词语在西班牙语中只翻译成 2 个,“te amo”。所以应用这种架构,机器翻译模型能够返回比输入字符串更多或更少的单词。
你可能已经注意到隐藏状态中颜色的奇怪分布。这是为了说明 RNN 被称为短期记忆的问题。
 图17
短期记忆(Short-term memory)是由梯度消失问题引起的,这在其他神经网络架构中也很普遍。随着 RNN 处理更多步骤,它很难保留先前步骤的信息。如你所见,在最后的时间步中,“what”和“time”这两个词的信息几乎不存在。短期记忆和消失梯度是由于反向传播(种用于训练和优化神经网络的算法)的性质造成的。要理解为什么会这样,让我们来看看反向传播对深度前馈神经网络的影响。
训练神经网络包括三个主要步骤。首先,它进行前向传递并进行预测。其次,它使用损失函数将预测与真实情况进行比较。损失函数输出一个误差值,它是对网络性能有多差的估计。最后,它使用该误差值进行反向传播,计算网络中每个节点的梯度。
图17
短期记忆(Short-term memory)是由梯度消失问题引起的,这在其他神经网络架构中也很普遍。随着 RNN 处理更多步骤,它很难保留先前步骤的信息。如你所见,在最后的时间步中,“what”和“time”这两个词的信息几乎不存在。短期记忆和消失梯度是由于反向传播(种用于训练和优化神经网络的算法)的性质造成的。要理解为什么会这样,让我们来看看反向传播对深度前馈神经网络的影响。
训练神经网络包括三个主要步骤。首先,它进行前向传递并进行预测。其次,它使用损失函数将预测与真实情况进行比较。损失函数输出一个误差值,它是对网络性能有多差的估计。最后,它使用该误差值进行反向传播,计算网络中每个节点的梯度。
 图18
梯度是用于调整网络内部权重的值,允许网络学习。梯度越大,调整越大,反之亦然。这就是问题所在。在进行反向传播时,一层中的每个节点都会根据梯度的影响计算它在它之前的层中的梯度。所以如果对之前层的调整很小,那么对当前图层的调整会更小。
这会导致梯度在向下传播时呈指数收缩。由于梯度极小,内部权重几乎没有调整,因此较早的层无法进行任何学习。这就是梯度消失问题。
图18
梯度是用于调整网络内部权重的值,允许网络学习。梯度越大,调整越大,反之亦然。这就是问题所在。在进行反向传播时,一层中的每个节点都会根据梯度的影响计算它在它之前的层中的梯度。所以如果对之前层的调整很小,那么对当前图层的调整会更小。
这会导致梯度在向下传播时呈指数收缩。由于梯度极小,内部权重几乎没有调整,因此较早的层无法进行任何学习。这就是梯度消失问题。
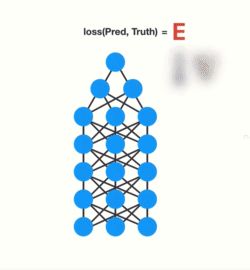 图19
让我们看看这如何应用于循环神经网络。你可以将循环神经网络中的每个时间步(time step)视为一个层。要训练循环神经网络,您可以使用时间反向传播(back-propagation through time)算法。梯度值将随着它在每个时间步长中传播而呈指数缩小。
图19
让我们看看这如何应用于循环神经网络。你可以将循环神经网络中的每个时间步(time step)视为一个层。要训练循环神经网络,您可以使用时间反向传播(back-propagation through time)算法。梯度值将随着它在每个时间步长中传播而呈指数缩小。
 图20
同样,梯度用于调整神经网络的权重,从而使其能够学习。小的梯度意味着小的调整。这会导致早期层无法学习。
在循环神经网络中,获得小梯度更新的层会停止学习。这些通常是较早的层。因此,因为这些层不学习,RNN 可以忘记它在较长序列中看到的内容,从而具有短期记忆(short-term memory)。
LSTM 和 GRU 是作为短期记忆的解决方案而创建的。它们具有称为门(gate)的内部机制,可以调节信息流。
图20
同样,梯度用于调整神经网络的权重,从而使其能够学习。小的梯度意味着小的调整。这会导致早期层无法学习。
在循环神经网络中,获得小梯度更新的层会停止学习。这些通常是较早的层。因此,因为这些层不学习,RNN 可以忘记它在较长序列中看到的内容,从而具有短期记忆(short-term memory)。
LSTM 和 GRU 是作为短期记忆的解决方案而创建的。它们具有称为门(gate)的内部机制,可以调节信息流。
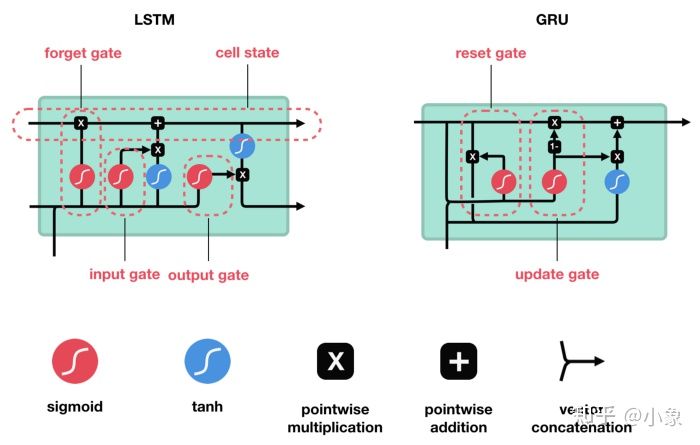 图21
这些gates知道序列中哪些数据是重要的需要保留,哪些需要丢弃。通过这样做,它可以将相关信息沿着长序列链传递下去,并且最后做出预测。几乎所有基于循环神经网络的输出都是通过这两个网络实现的。 LSTM 和 GRU 可以在语音识别、语音合成和文本生成中找到。你甚至可以使用它们为视频生成字幕。
图21
这些gates知道序列中哪些数据是重要的需要保留,哪些需要丢弃。通过这样做,它可以将相关信息沿着长序列链传递下去,并且最后做出预测。几乎所有基于循环神经网络的输出都是通过这两个网络实现的。 LSTM 和 GRU 可以在语音识别、语音合成和文本生成中找到。你甚至可以使用它们为视频生成字幕。
LSTM And GRU
Review of Recurrent Neural Networks
要了解 LSTM 或 GRU 如何实现这一点,让我们回顾一下循环神经网络。 RNN 是这样工作的;第一个词被转换成机器可读的向量。然后 RNN 将向量序列一一处理。
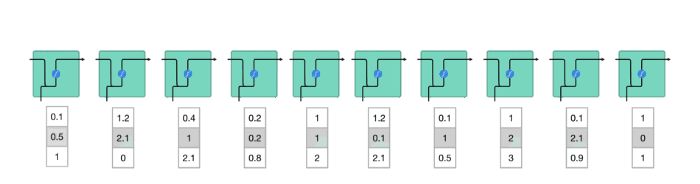 图22
在处理时,它将先前的隐藏状态传递到序列的下一步。隐藏状态充当神经网络的记忆。它保存有关网络之前看到的先前数据的信息。
图22
在处理时,它将先前的隐藏状态传递到序列的下一步。隐藏状态充当神经网络的记忆。它保存有关网络之前看到的先前数据的信息。
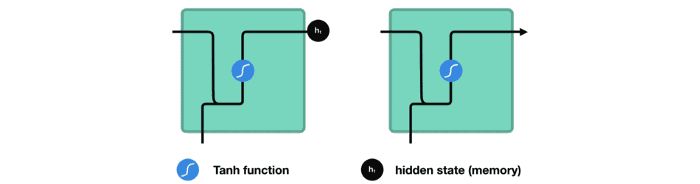 图23
让我们看一下 RNN 的一个单元格,看看如何计算隐藏状态。首先,将输入和先前的隐藏状态组合起来形成一个向量。该向量现在具有有关当前输入和先前输入的信息。向量经过 tanh 激活,输出是新的隐藏状态,或者称为网络的记忆。
图23
让我们看一下 RNN 的一个单元格,看看如何计算隐藏状态。首先,将输入和先前的隐藏状态组合起来形成一个向量。该向量现在具有有关当前输入和先前输入的信息。向量经过 tanh 激活,输出是新的隐藏状态,或者称为网络的记忆。
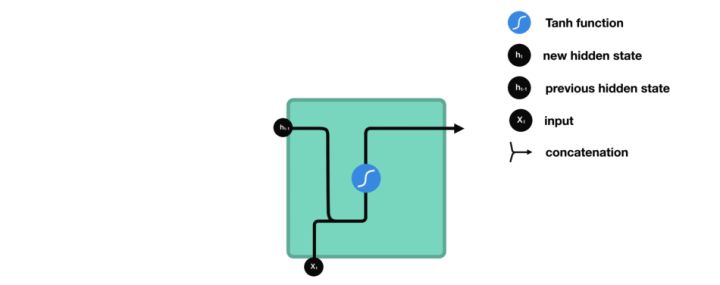 图24
图24
Tanh activation
 图25
当向量流经神经网络时,由于各种数学运算,它会经历许多变换。所以想象一个值继续乘以 3。你可以看到一些值如何爆炸并变得天文数字,导致其他值看起来微不足道。
图25
当向量流经神经网络时,由于各种数学运算,它会经历许多变换。所以想象一个值继续乘以 3。你可以看到一些值如何爆炸并变得天文数字,导致其他值看起来微不足道。
 图26
tanh 函数确使得值保持在 -1 和 1 之间,从而调节神经网络的输出。您可以看到上面的相同值如何保留在 tanh 函数允许的边界之间。如下图所示
图26
tanh 函数确使得值保持在 -1 和 1 之间,从而调节神经网络的输出。您可以看到上面的相同值如何保留在 tanh 函数允许的边界之间。如下图所示
 图27
这就是一个 RNN。它的内部操作很少,但在适当的情况下(如短序列)运行良好。 RNN 使用的计算资源比它的进化变体、LSTM 和 GRU 少得多。
图27
这就是一个 RNN。它的内部操作很少,但在适当的情况下(如短序列)运行良好。 RNN 使用的计算资源比它的进化变体、LSTM 和 GRU 少得多。
LSTM
接下来具体看下LSTM的结构
LSTM 具有与循环神经网络类似的控制流程。它在信息向前传播时处理传递信息的数据。不同之处在于 LSTM 单元内的操作。
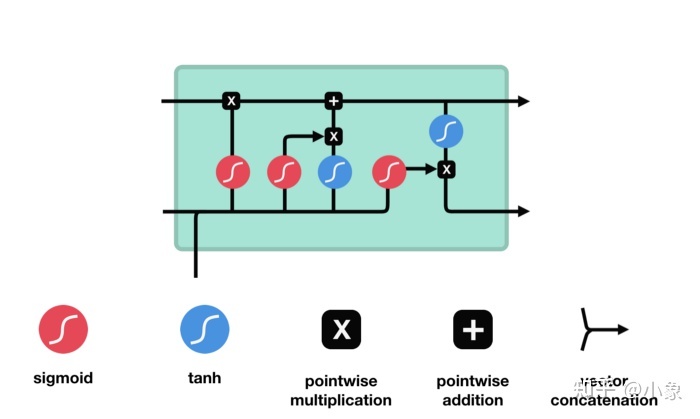 图28
图28
Sigmoid
这些操作用于允许 LSTM 保留或忘记信息。现在查看这些操作可能会让人有点不知所措,因此我们将逐步介绍这一点。
Core Concept
LSTM 的核心概念是细胞状态(cell state),它是各种门结构(gates)。细胞状态充当传输高速公路,在序列链中一直传输相关信息。您可以将其视为网络的“记忆”。理论上,细胞状态可以在序列的整个处理过程中携带相关信息。因此,即使是来自较早时间步的信息也可以进入较晚的时间步,从而减少短期记忆的影响。随着细胞状态继续前进,信息通过门被添加或删除到细胞状态。门是不同的神经网络,它们决定在细胞状态中允许哪些信息。门可以学习在训练期间保留或忘记哪些相关信息。
Gates 包含 sigmoid 激活函数。 sigmoid 激活类似于 tanh 激活。它不是将值压缩到 -1 和 1 之间,而是将值压缩到 0 和 1 之间。这有助于更新或忘记数据,因为任何乘以 0 的数字都是 0,从而导致值消失或被“遗忘”。任何乘以 1 的数字都是相同的值,因此该值保持不变或“保留”。网络可以了解哪些数据不重要因此可以被遗忘或哪些数据重要需要保留。
 图29
让我们更深入地了解一下各个门在做什么吧。我们有三个不同的门来调节 LSTM 单元中的信息流。遗忘门(Forget gate)、输入门(Input gate)和输出门(Cell gate)。
图29
让我们更深入地了解一下各个门在做什么吧。我们有三个不同的门来调节 LSTM 单元中的信息流。遗忘门(Forget gate)、输入门(Input gate)和输出门(Cell gate)。
Forget gate
首先,我们有遗忘门。这个门决定应该丢弃或保留哪些信息。来自先前隐藏状态的信息和来自当前输入的信息通过 sigmoid 函数传递。值介于 0 和 1 之间。越接近 0 表示忘记,越接近 1 表示保留。
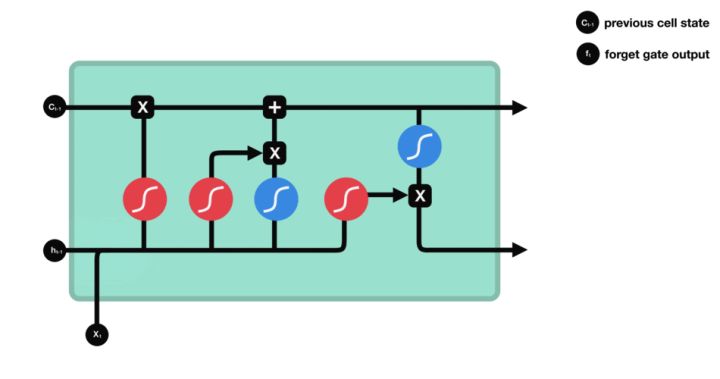 图30
图30
Input Gate
为了更新细胞状态,我们有输入门。首先,我们将先前的隐藏状态和当前输入传递给一个 sigmoid 函数。这通过将值转换为 0 和 1 之间来决定更新哪些值。0 表示不重要,1 表示重要。您还将隐藏状态和当前输入传递到 tanh 函数中,以压缩 -1 和 1 之间的值,以帮助调节网络。然后将 tanh 输出与 sigmoid 输出相乘。 sigmoid 输出将决定从 tanh 输出中保留哪些重要信息。
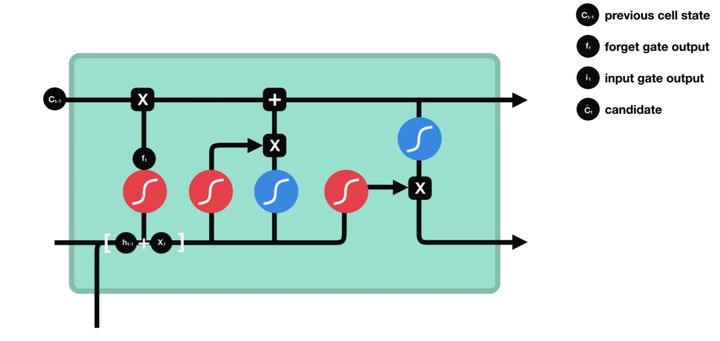 图31
图31
Cell State
现在我们应该有足够的信息来计算细胞状态。首先,单元状态逐点乘以遗忘向量。如果单元格状态乘以接近 0 的值,则有可能丢弃单元格状态中的值。然后我们从输入门中获取输出并进行逐点加法,将单元格状态更新为神经网络认为相关的新值。给予了我们新的细胞状态。
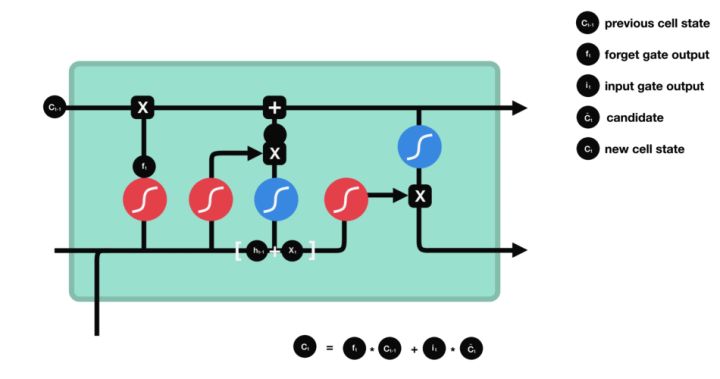 图32
图32
Output Gate
最后是输出门。输出门决定下一个隐藏状态是什么。请记住,隐藏状态包含有关先前输入的信息。隐藏状态也用于预测。首先,我们将先前的隐藏状态和当前输入传递给一个 sigmoid 函数。然后我们将新修改的细胞状态传递给 tanh 函数。我们将 tanh 输出与 sigmoid 输出相乘来决定隐藏状态应该携带什么信息。输出是隐藏状态。新的细胞状态和新的隐藏状态之后被转移到下一个时间步。
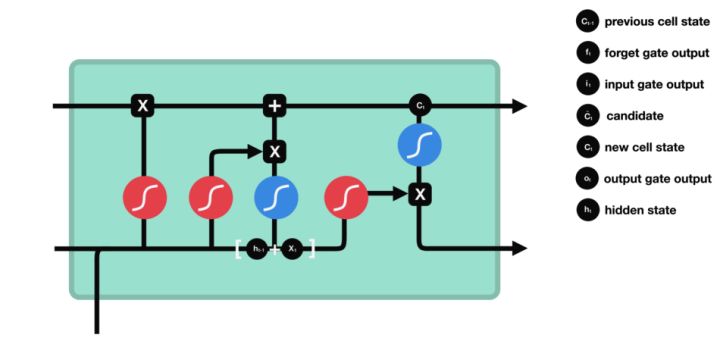 图33
总结一下,忘记门决定什么是与先前步骤相关的。输入门决定从当前步骤添加哪些信息是相关的。输出门决定下一个隐藏状态应该是什么。
图33
总结一下,忘记门决定什么是与先前步骤相关的。输入门决定从当前步骤添加哪些信息是相关的。输出门决定下一个隐藏状态应该是什么。
Code Demo
使用 python 伪代码的示例
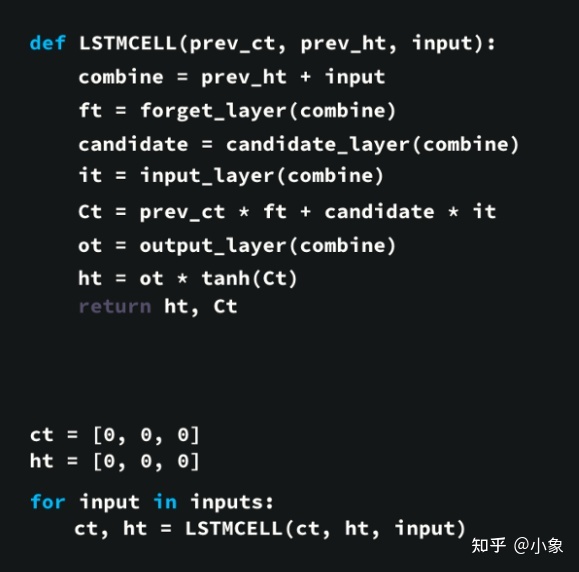 图34
首先,将先前的隐藏状态和当前输入连接起来。我们称之为combine。
将combine输入到遗忘层中。该层删除不相关的数据。
使用combine创建候选层。候选层拥有要添加到细胞状态的可能值。
combine也被输入到输入层。该层决定应将来自候选者的哪些数据添加到新的细胞状态。
在计算完遗忘层、候选层和输入层后,使用这些向量和先前的细胞状态计算细胞状态。
计算输出值。
逐点乘以输出和新的细胞状态为我们提供了新的隐藏状态。
LSTM 网络的控制流程是一些张量操作和一个 for 循环。你可以使用隐藏状态进行预测。结合所有这些机制,LSTM 可以选择在序列处理期间记住或忘记哪些相关信息。
图34
首先,将先前的隐藏状态和当前输入连接起来。我们称之为combine。
将combine输入到遗忘层中。该层删除不相关的数据。
使用combine创建候选层。候选层拥有要添加到细胞状态的可能值。
combine也被输入到输入层。该层决定应将来自候选者的哪些数据添加到新的细胞状态。
在计算完遗忘层、候选层和输入层后,使用这些向量和先前的细胞状态计算细胞状态。
计算输出值。
逐点乘以输出和新的细胞状态为我们提供了新的隐藏状态。
LSTM 网络的控制流程是一些张量操作和一个 for 循环。你可以使用隐藏状态进行预测。结合所有这些机制,LSTM 可以选择在序列处理期间记住或忘记哪些相关信息。
GRU
所以现在我们知道了 LSTM 的工作原理,让我们简要地看看 GRU。 GRU 是新一代的循环神经网络,与 LSTM 非常相似。 GRU 摆脱了细胞状态并使用隐藏状态来传输信息。它只有两个门,一个复位门和一个更新门。
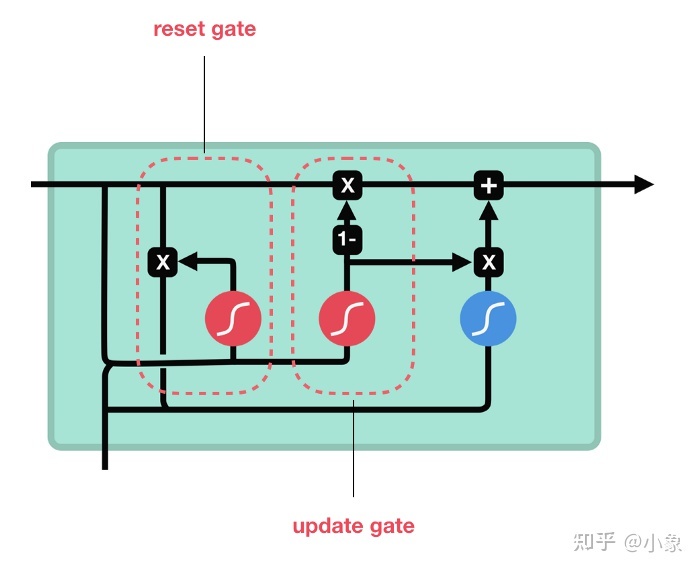 图35
图35
Update Gate
更新门的作用类似于 LSTM 的遗忘门和输入门。它决定丢弃哪些信息以及添加哪些新信息。
Reset Gate
重置门是另一个门,用于决定忘记多少过去的信息。 这就是一个 GRU的结构。 GRU 的张量运算较少;因此,它们的训练速度比 LSTM 快一些。目前没有证据说明这俩哪一个更好。研究人员和工程师通常会同时尝试确定哪一种更适合他们的项目。
总结一下
RNN 适合处理用于预测的序列数据,但会受到短期记忆的影响。 LSTM 和 GRU 是作为一种使用称为门的机制来减轻短期记忆的方法而创建的。门只是调节流经序列链的信息流的神经网络。 LSTM 和 GRU 用于最先进的深度学习应用程序,如语音识别、语音合成、自然语言理解等。
练习
此示例使用 MNIST 手写数字。该数据集包含 60,000 个用于训练的示例和 10,000 个用于测试的示例。这些数字已经过大小标准化并以固定大小的图像(28x28 像素)为中心,值从 0 到 1。为简单起见,每个图像都被展平并转换为 784 个特征(2828 )。
 图36
为了使用循环神经网络对图像进行分类,我们将每个图像行视为一个像素序列。由于 MNIST 图像形状为 2828px,因此我们将为每个样本处理 28 个 28 个时间步长的序列。
首先,导入用到的库:
图36
为了使用循环神经网络对图像进行分类,我们将每个图像行视为一个像素序列。由于 MNIST 图像形状为 2828px,因此我们将为每个样本处理 28 个 28 个时间步长的序列。
首先,导入用到的库:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM
加载数据:
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
显示任意一张图像:
def show_single_image(img_arr):
plt.imshow(img_arr, cmap="binary")
plt.show()
show_single_image(x_train[0])
 图37
图37
x_train = x_train / 255.0
x_test = x_test / 255.0
模型定义:
model = Sequential()
model.add(LSTM(128, input_shape=(x_train.shape[1:]), activation='relu', return_sequences=True)) #x_train.shape=(60000, 28, 28)
model.add(Dropout(0.2))
model.add(LSTM(128, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
定义优化器、损失函数等:
opt = tf.keras.optimizers.Adam(lr=1e-3, decay=1e-5)
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt,
metrics=['accuracy'])
模型训练:
history = model.fit(x_train, y_train, epochs=3, validation_data=(x_test, y_test))
 图38
模型保存:
图38
模型保存:
model.save('Minst_Lstm.model')