在前两篇文章中,我们学习了如何从密集层(dense)的堆栈中构建完全连接的网络。首次创建时,网络的所有权重都是随机设置的——网络尚不“知道”任何事情。在本节中,我们将了解如何训练神经网络;我们将看到神经网络是如何学习的。 与所有机器学习任务一样,我们从一组训练数据开始。训练数据中的每个示例都包含一些特征(输入)和一个预期目标(输出)。训练网络意味着以一种可以将特征转换为目标的方式调整其权重。例如,在 80 Cereals 数据集中,我们想要一个网络,它可以获取每种谷物的“糖”、“纤维”和“蛋白质”含量,并预测该谷物的“卡路里”。如果我们能成功地训练一个网络来做到这一点,它的权重必须以某种方式表示这些特征与目标之间的关系。 除了训练数据,我们还需要两件事: - 衡量网络预测效果的“损失函数”。 - 一个“优化器”,可以告诉网络如何改变它的权重。
The Loss Function
我们已经看到了如何为网络设计架构,但我们还没有看到如何告诉网络要解决什么问题。这就是损失函数的工作。
损失函数衡量目标的真实值与模型预测值之间的差异。
不同的问题需要不同的损失函数。我们一直在研究回归问题,其中的任务是预测一些数值——80 Cereals中的卡路里,红酒质量的评级。其他回归任务可能是预测房屋价格或汽车的燃油效率。
回归问题的常见损失函数是平均绝对误差或 MAE。对于每个预测 y_pred,MAE 通过绝对差 abs(y_true - y_pred) 测量与真实目标 y_true 的差异。
数据集上的总 MAE 损失是所有这些绝对差异的平均值。
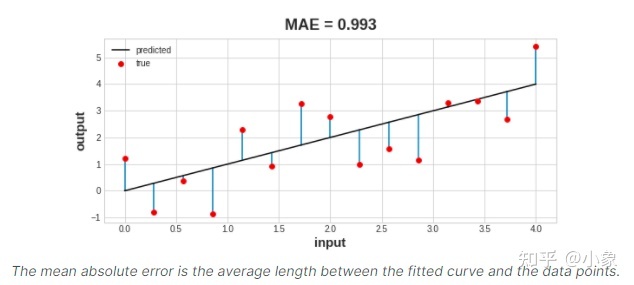
除了 MAE,我们可能会在回归问题中看到的其他损失函数是均方误差 (MSE) 或 Huber 损失(两者都在 Keras 中可用)等。 在训练过程中,模型将使用损失函数作为寻找正确权重值的指南(损失越小越好)。换句话说,损失函数告诉网络它的目标。
The Optimizer - Stochastic Gradient Descent
我们已经描述了我们希望网络模型解决的问题,但现在我们需要知道如何解决它。这是优化器的工作。优化器是一种调整权重以最小化损失的算法。
实际上,深度学习中使用的所有优化算法都属于称为随机梯度下降(stochastic gradient descent)的家族。它们是逐步训练网络的迭代算法。训练的一个步骤是这样的:
- 1.采样一些训练数据并通过网络运行它以进行预测。
- 2.测量预测值和真实值之间的损失。
- 3.最后,在使损失更小的方向上调整权重。
然后一遍又一遍地这样做,直到损失尽可能小(或者直到它不会进一步减少。)
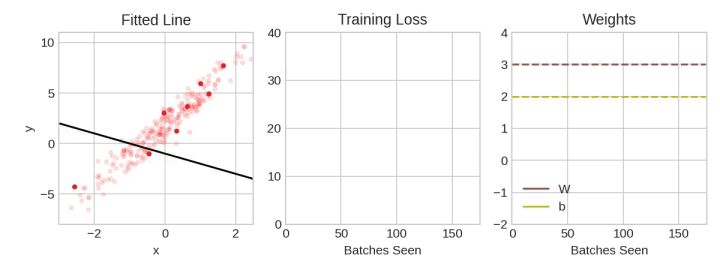
每次迭代的训练数据样本称为小批量(minibatch)(或通常简称为“批次(batch)”),而完整的一轮训练数据称为一个epoch。您训练的epoch数是网络模型将看到每个训练示例的次数。 为什么用批次的概念? 上边的动画显示了线性模型正在使用 SGD 进行训练。淡红点描绘了整个训练集,而实心红点是小批量。每次 SGD 看到一个新的 minibatch 时,它都会将权重(w 斜率和 b 截距)移向该批次的正确值。一批又一批,线最终收敛到最佳拟合。可以看到,随着权重越来越接近其真实值,损失越来越小。
Learning Rate and Batch Size
请注意,该线仅在每个批次的方向上进行小幅移动(而不是一直移动)。这些变化的大小由学习率(learning rate)决定。较小的学习率意味着网络在其权重收敛到最佳值之前需要看到更多的小批量。 学习率和批量的大小是对 SGD 训练过程影响最大的两个参数。它们的相互作用通常是微妙的,这些参数的正确选择并不总是显而易见的。 幸运的是,对于大多数工作,我们不需要进行大量的超参数搜索来获得满意的结果。 Adam 是一种 SGD 算法,具有自适应学习率,它可以适用于大多数问题而无需任何参数调整(从某种意义上说,它是“自调整”)。 Adam 是一个很棒的通用优化器。 你知道还有哪些优化器吗?检索一下~
Adding the Loss and Optimizer
定义模型后,可以使用模型的 compile 方法添加损失函数和优化器: model.compile( optimizer="adam", loss="mae", )
请注意,我们可以仅用一个字符串来指定损失和优化器。更多的可选参数,可以查看 Keras API 。
练习
在本练习中,您将在Fuel Economy数据集上训练神经网络,然后探索学习率和批量大小对 SGD 的影响。 在Fuel Economy数据集中,我们的任务是根据发动机类型或制造年份等特征预测汽车的燃油消费情况。
import matplotlib.pyplot as plt
from tools.dltools import animate_sgd
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('animation', html='html5')
首先要导包,也就是导入我们需要的库
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer, make_column_selector
from sklearn.model_selection import train_test_split
%matplotlib inline
然后,加载数据
# load file
fuel = pd.read_csv('datasets/fuel.csv')
X = fuel.copy()
# Remove target
y = X.pop('FE')
preprocessor = make_column_transformer(
(StandardScaler(),
make_column_selector(dtype_include=np.number)),
(OneHotEncoder(sparse=False),
make_column_selector(dtype_include=object)),
)
X = preprocessor.fit_transform(X)
y = np.log(y) # log transform target instead of standardizing
input_shape = [X.shape[1]]
print("Input shape: {}".format(input_shape))
可以打印输出部分数据进行查看,我们的目标是“FE”列,其余列是特征。 pd.DataFrame(X[:10,:]).head()

# 定义一个简单的模型
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1),
])
在训练网络之前,我们需要定义我们将使用的损失和优化器。使用模型的compile方法,添加 Adam 优化器和 MAE 损失。
model.compile(optimizer='adam',
loss='mae')
定义模型并使用损失和优化器对其进行编译后,就可以进行训练了。以 128 的批量大小训练网络 200 个 epoch。输入数据是 X,目标是 y。
history = model.fit(X,y ,
batch_size=128,
epochs=100)
部分运行截图如下:

最后一步是查看损失曲线并评估训练。运行下面的单元格以获取训练损失图。
import pandas as pd
history_df = pd.DataFrame(history.history)
# Start the plot at epoch 5. You can change this to get a different view.
history_df.loc[5:, ['loss']].plot();
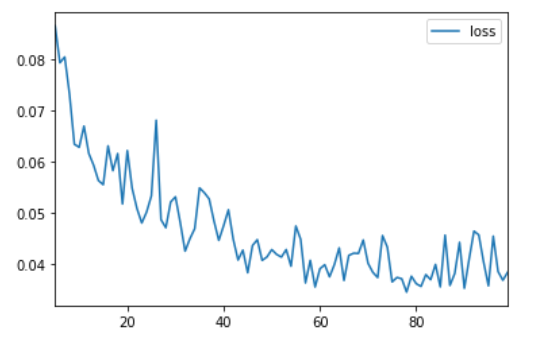
如果你对模型进行更长时间的训练,你是否预计损失会进一步减少?
这取决于训练过程中损失的演变方式:如果学习曲线趋于平稳,那么训练额外的 epoch 通常不会有任何优势。相反,如果损失似乎仍在减少,那么更长时间的训练可能是有利的。
通过学习率和批量大小,您可以控制:
- 训练一个模型需要多长时间
- 学习曲线有多嘈杂
- 损失变得多小
为了更好地理解这两个参数,我们将查看线性模型,即我们最简单的神经网络。只有一个权重和一个偏差,更容易看出参数变化的影响。
更改 learning_rate、batch_size 和 num_examples(有多少数据点)的值,然后训练我们的模型。 尝试以下组合,或尝试您自己的一些组合:
# 代码执行会有点慢,需稍等下
learning_rate = 0.05
batch_size = 32
num_examples = 256
animate_sgd(
learning_rate=learning_rate,
batch_size=batch_size,
num_examples=num_examples,
# You can also change these, if you like
steps=50, # total training steps (batches seen)
true_w=3.0, # the slope of the data
true_b=2.0, # the bias of the data
)
这里执行代码后悔生成一个动图,大家自己运行看下效果吧~ 更改这些参数有什么影响?考虑一下 您可能已经看到较小的批次大小会产生噪声较大的权重更新和损失曲线。这是因为每个批次都是一个小数据样本,较小的样本往往会给出更嘈杂的估计。较小的批次可以具有“平均”效果,尽管这可能是有益的。 学习率越小,更新越小,训练收敛时间越长。大的学习率可以加快训练速度,但也不要“适应”到最低限度。当学习率太大时,训练可能完全失败。 (尝试将学习率设置为较大的值,例如 0.99 以查看这一点。)