What is Deep Learning?
近年来,人工智能领域一些最令人印象深刻的进步是在深度学习领域。自然语言翻译、图像识别等任务,应用深度学习模型已经接近甚至超过人类的水平了。 那么什么是深度学习?深度学习是一种以深度计算为特征的机器学习方法。这种计算深度使深度学习模型能够理清在复杂数据集中发现的各种复杂模式。 通过其强大的功能和可扩展性,神经网络(neural networks)已成为深度学习的基础模型。神经网络由神经元组成,其中每个神经元单独执行一个简单的计算。事实上,神经网络的力量正是来自于这些神经元之间形成的复杂链接。
The Linear Unit
我们从神经网络的基本组成部分开始:单个神经元。如图所示,表示的是只有一个输入的神经元(或单元):
 输入是 x,它与神经元的连接权重(weight)为 w。每当一个值流经一个连接时,我们就将该值乘以该连接的权重。对于输入 x,到达神经元的是 w x。神经网络通过修改其权重来“学习”。
b 是一种特殊的权重,我们称之为偏差(bias)。偏差没有任何与之相关的输入数据;相反,我们在图中放了一个 1,这样到达神经元的值就是 b(因为 1 b = b)。偏置使神经元能够独立于其输入修改输出。
y 是神经元最终输出的值。为了获得输出,神经元将通过其连接接收到的所有值相加。这个神经元的激活公式是 y = w x + b,或者作为一个公式 y=wx+b 。
有没有觉得公式 y = wx + b很熟悉呢?
这是一条直线的方程!这是斜率截距方程,其中 w 是斜率,b 是 y 截距。
输入是 x,它与神经元的连接权重(weight)为 w。每当一个值流经一个连接时,我们就将该值乘以该连接的权重。对于输入 x,到达神经元的是 w x。神经网络通过修改其权重来“学习”。
b 是一种特殊的权重,我们称之为偏差(bias)。偏差没有任何与之相关的输入数据;相反,我们在图中放了一个 1,这样到达神经元的值就是 b(因为 1 b = b)。偏置使神经元能够独立于其输入修改输出。
y 是神经元最终输出的值。为了获得输出,神经元将通过其连接接收到的所有值相加。这个神经元的激活公式是 y = w x + b,或者作为一个公式 y=wx+b 。
有没有觉得公式 y = wx + b很熟悉呢?
这是一条直线的方程!这是斜率截距方程,其中 w 是斜率,b 是 y 截距。
Example - The Linear Unit as a Model
尽管单个神经元通常仅作为更大网络的一部分起作用,但以单个神经元模型作为基线开始通常很有用。单神经元模型是线性模型。
让我们思考一下在 80 Cereals这样的数据集上模型是如何工作的。简单看下这个数据集的介绍:
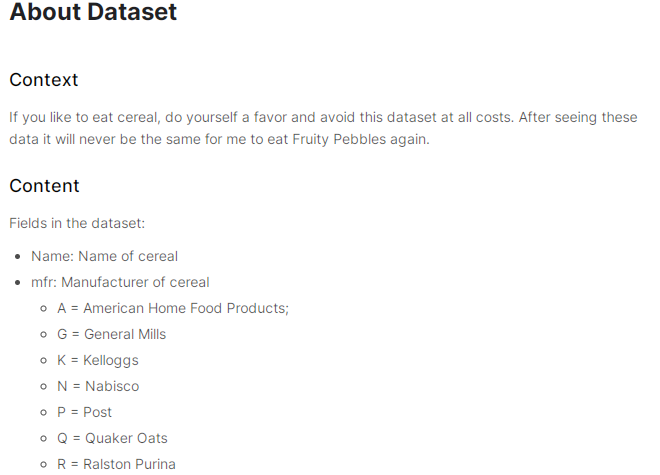
 可以看到,这个数据集有很多特征(也就是列),以“糖”(每份糖的克数)为输入,以“卡路里”(每份卡路里)为输出来训练模型,我们可能会发现偏差为 b=90,权重为 w=2.5。我们可以这样估算每份含 5 克糖的谷物的卡路里含量:
可以看到,这个数据集有很多特征(也就是列),以“糖”(每份糖的克数)为输入,以“卡路里”(每份卡路里)为输出来训练模型,我们可能会发现偏差为 b=90,权重为 w=2.5。我们可以这样估算每份含 5 克糖的谷物的卡路里含量:
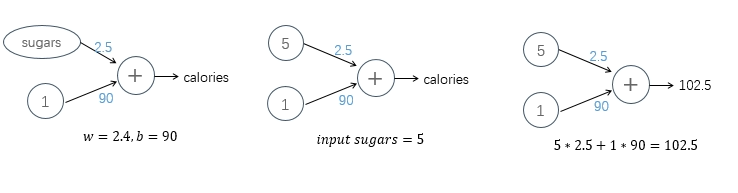 对照我们的公式,我们计算得到卡路里=2.5×5+90=102.5 ,跟我们预期的一样。
对照我们的公式,我们计算得到卡路里=2.5×5+90=102.5 ,跟我们预期的一样。
Multiple Inputs
80 Cereals 数据集具有的特征远不止“糖”这一种。如果我们想扩展模型,让其包含"纤维"或"蛋白质含量"等内容该怎么办?其实这很容易。我们可以向神经元添加更多输入连接,每个链接对应一个特征。为了得到最终的输出结果,我们将每个输入与其连接权重相乘,然后将它们加在一起。
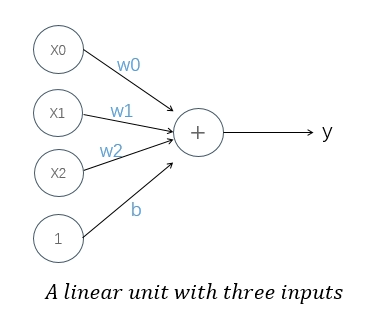 这个神经元的公式是 y = w0 x0 + w1 x1 + w2 * x2 + b 。具有两个输入的线性单元将得到一个平面,而具有更多输入的单元将得到一个超平面。
这个神经元的公式是 y = w0 x0 + w1 x1 + w2 * x2 + b 。具有两个输入的线性单元将得到一个平面,而具有更多输入的单元将得到一个超平面。
Linear Units in Keras
在 Keras 中创建模型的最简单方法是通过 keras.Sequential,它将神经网络创建为层堆栈。我们可以使用dense层(我们将在下一节中了解更多信息)来创建与上述类似的模型。 我们可以定义一个线性模型,接受三个输入特征(“糖”、“纤维”和“蛋白质”)并产生一个输出(“卡路里”),如下所示:
from tensorflow import keras
from tensorflow.keras import layers
# Create a network with 1 linear unit
model = keras.Sequential([
layers.Dense(units=1, input_shape=[3])
])
使用第一个参数units,我们定义了我们想要的输出数量。在当前例子中,我们只是预测“卡路里”,因此我们将使用units=1。 使用第二个参数 input_shape,我们告诉 Keras 输入的维度。设置 input_shape=[3] 确保模型将接受三个特征作为输入(“糖”、“纤维”和“蛋白质”)。 现在,一个简单的模型就构建好了,可以传入数据进行训练了。
练习
在前边的内容中,我们了解了神经网络的构建模块:线性单元(linear units)。我们看到只有一个线性单元的模型将线性函数拟合到数据集(相当于线性回归)。在本练习中,我们将构建一个线性模型并获得一些在 Keras 中使用模型的练习。 我们用到的数据集:red-wine。红酒数据集由大约 1600 种葡萄牙红葡萄酒的理化测量值组成。还包括盲品测试对每种葡萄酒的质量评级。
# 首先我们读入数据集,并打印部分数据看看
import pandas as pd
red_wine=pd.read_csv('wineQualityReds.csv')
red_wine.head()

通过shape我们可以得到数据集的行列数
red_wine.shape #输出(1599, 12)
我们如何能从物理化学测量中预测葡萄酒的质量呢? “quality”这列会作为模型target,也就是模型输出的期望值,其余列是特征。在此任务中,考虑下你将如何为 Keras 模型设置 input_shape 参数? input_shape = [11]
为什么 input_shape 是 Python 列表? 我们使用的数据是表格数据,就像 Pandas中的dataframe格式。我们将为数据集中的每个特征提供一个输入。特征按列排列,所以我们总是有 input_shape=[num_columns]。 Keras 在这里使用列表的原因是允许使用更复杂的数据集。例如,图像数据可能需要三个维度:[高度、宽度、通道]。 现在定义适合此任务的线性模型。注意模型应该有多少输入和输出。
from tensorflow import keras
from tensorflow.keras import layers
# YOUR CODE HERE
model = keras.Sequential([
layers.Dense(units=1, input_shape=[11])
])
Keras 用张量表示神经网络的权重。张量基本上是 TensorFlow 版本的 Numpy 数组,但有一些差异,使它们更适合深度学习。最重要的一点是张量与 GPU 和 TPU加速器兼容。事实上,TPU 是专门为张量计算而设计的。 模型的权重作为张量列表保存在它的权重属性中。获取我们在上面定义的模型的权重(可以直接用print进行打印输出:print("Weights\n{}\n\nBias\n{}".format(w, b))。
w, b = model.weights
print("Weights\n{}\n\nBias\n{}".format(w, b))

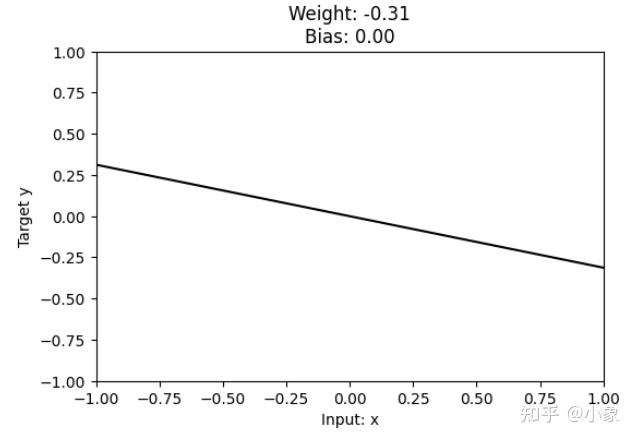
如果处理的问题类型是回归问题,其目标是预测某个具体的数字。回归问题就像“曲线拟合”问题:我们试图找到一条最适合数据的曲线。我们来看看线性模型产生的“曲线”。 (你可能已经猜到这是一条线!) 我们提到在训练模型之前,权重是随机设置的。运行下面的单元格几次以查看随机初始化生成的不同行。
import tensorflow as tf
import matplotlib.pyplot as plt
model = keras.Sequential([
layers.Dense(1, input_shape=[1]),
])
x = tf.linspace(-1.0, 1.0, 100)
y = model.predict(x)
plt.figure(dpi=100)
plt.plot(x, y, 'k')
plt.xlim(-1, 1)
plt.ylim(-1, 1)
plt.xlabel("Input: x")
plt.ylabel("Target y")
w, b = model.weights # you could also use model.get_weights() here
plt.title("Weight: {:0.2f}\nBias: {:0.2f}".format(w[0][0], b[0]))
plt.show()