70 BERT微调
目录
1.intro
与图片分类不同,BERT预训练时使用的两个任务没有什么实际应用场景,所以使用BERT时多需要进行微调。
BERT对每一个token都返回一个特定长度的特征向量(课堂演示为128,bert-base是768,bert-large是1024),这些特征向量抽取了上下文信息。不同的任务使用不同的特征。
2.具体应用
2.1句子分类
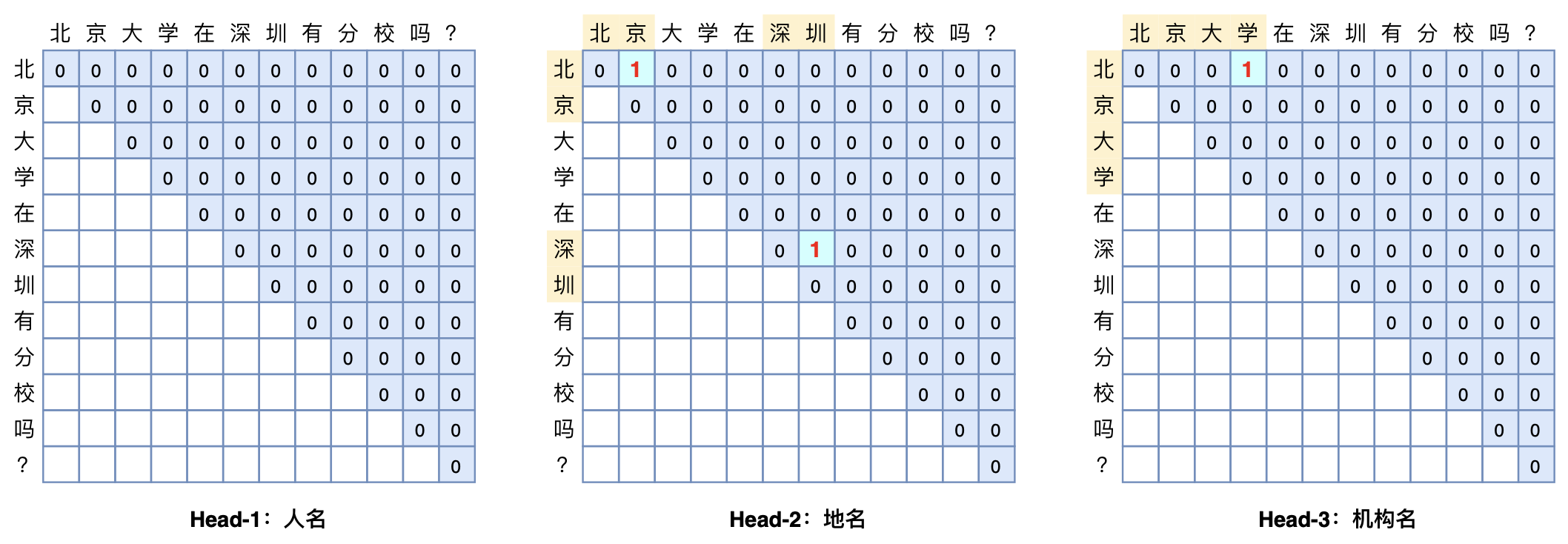
将句首的\<CLS>token对应的向量输入到全连接层分类。对于一对句子也是同理,句子中间用\<SEP
分类标签归档:深度学习
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是O(1)! 简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
 GlobalPoniter多头识别嵌套实体示意图
GlobalPoniter多头识别嵌套实体示意图
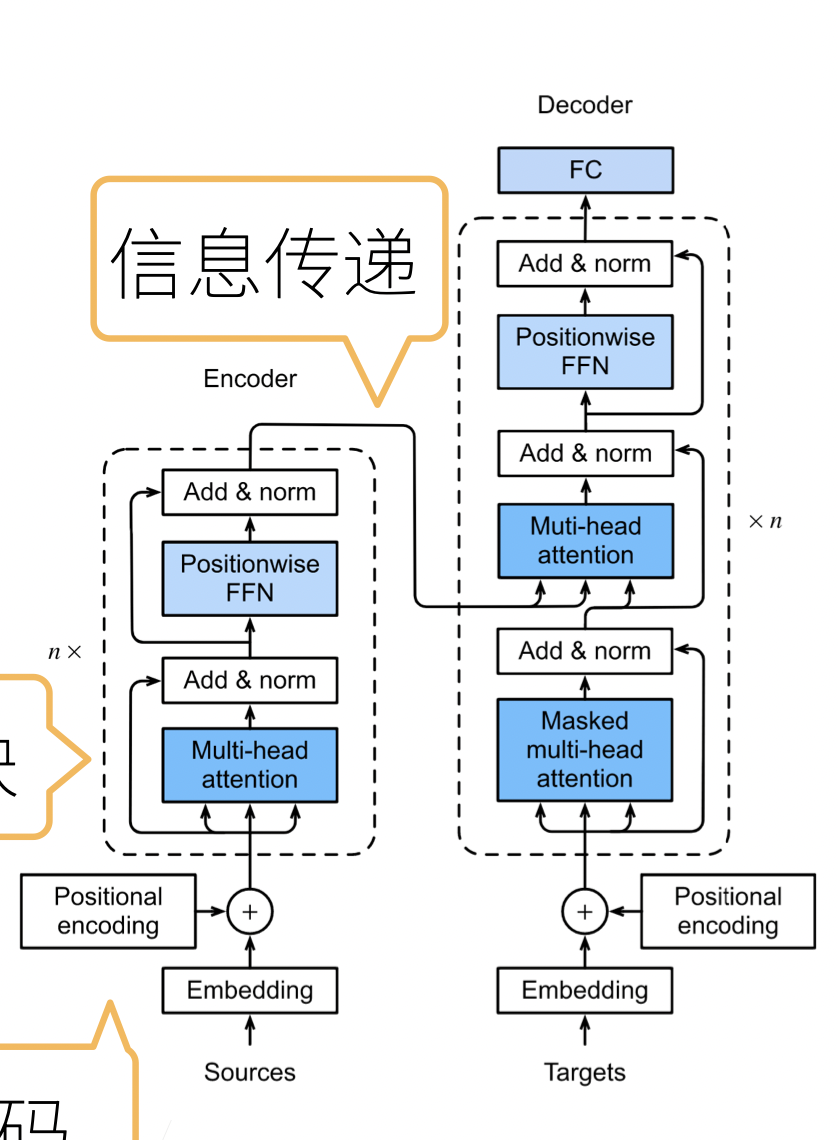
基于encoder-decoder架构来处理序列对
对同一key,value,query,希望抽取不同的信息
多头注意力使用h个独立的注意力池化

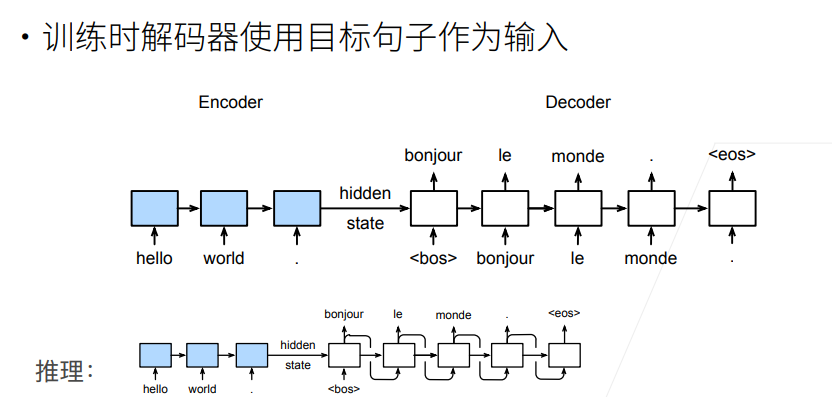
在序列生成问题中,常用的方法是一个个词元地进行生成,但是先前步生成的词元会影响之后词元的概率分布,为此,我们需要使用搜索算法来得到一个较好的序列
贪心搜索即每个时间步都选择具有最高条件概率的词元。 $$ y{t'} = \operatorname*{argmax}{y \in \mathcal{Y}} P(y \mid y1, \ldots, y{t'-1}, \mathbf{c}) $$ 我们的目标是找到一个最有序列,他的联合概率,也就是每步之间的条件概率的乘积,最大。 $$ \prod{t'=1}^{T'} P(y{t'} \mid y1, \ldots, y{t'-1}
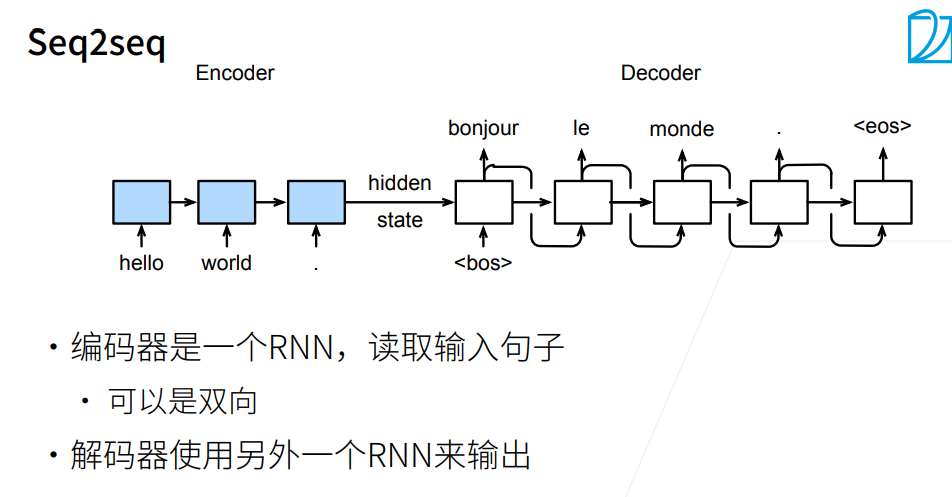
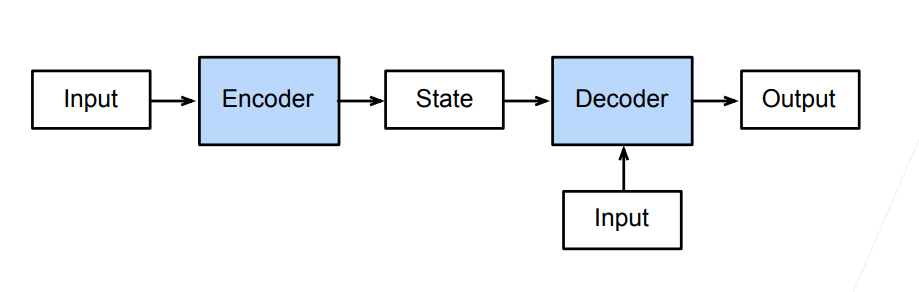
序列到序列模型由编码器-解码器构成。
编码器RNN可以是双向,由于输入的句子是完整地,可以正着看,也可以反着看;而解码器只能是单向,由于预测时,只能正着去预测。
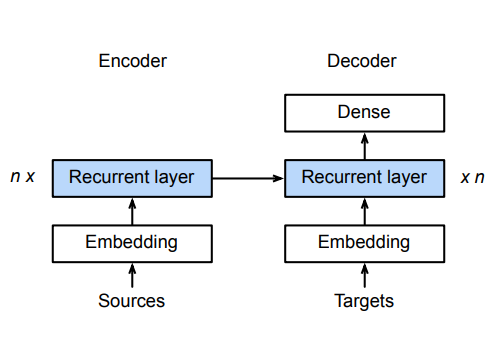
编码器的RNN没有连接输出层
编码器的最后时间步的隐状态用作解码器的初始隐状态(图中箭头的传递)
考虑一个CNN模型:
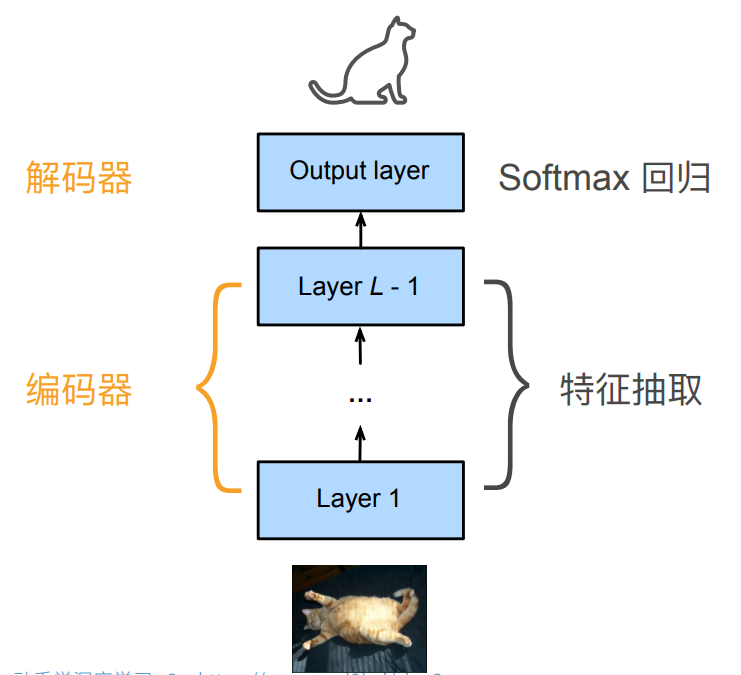 整个CNN实际上可以看作一个编码器,解码器两部分。
整个CNN实际上可以看作一个编码器,解码器两部分。
对于RNN而言,同样有着类似的划分

指一个模型被分为两块:
导读:在互联网新零售的大背景下,商品知识图谱作为新零售行业数字化的基石,提 供了对于商品相关内容的立体化、智能化、常识化的理解,对上层业务的落地起到了 至关重要的作用。相比于美团大脑中围绕商户的知识图谱而言,在新零售背景下的商 品知识图谱需要应对更加分散、复杂的数据和业务场景,而这些不同的业务对于底层 知识图谱都提出了各自不同的需求和挑战。美团作为互联网行业中新零售的新势力, 业务上已覆盖了包括外卖、商超、生鲜、药品等在内的多个新零售领域,技术上在相 关的知识图谱方面进行了深入探索。本文将对美团新零售背景下零售商品知识图谱的 构建和应用进行介绍。
近年来,人
之前讲的RNN都只有一个隐藏层(序列变长不算是深度),而一个隐藏层的RNN一旦做的很宽就容易出现过拟合。因此我们考虑将网络做的更深而非更宽,每层都只做一点非线性,靠层数叠加得到更加非线性的模型。
浅RNN:输入-隐层-输出
深RNN:输入-隐层-隐层-...-输出
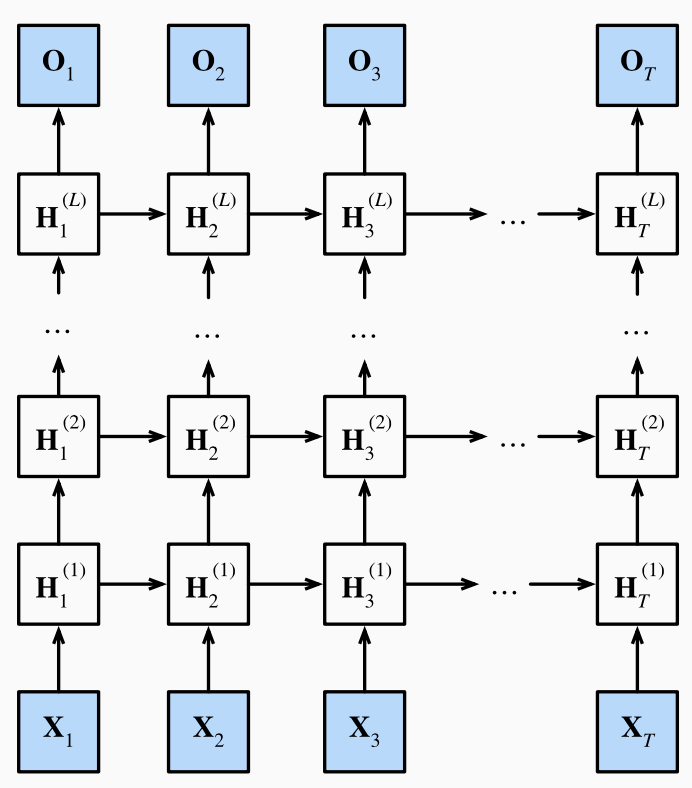 (课程视频中的图片有错误,最后输出层后一时间步是不受前一步影响的,即没有箭头)
(课程视频中的图片有错误,最后输出层后一时间步是不受前一步影响的,即没有箭头)