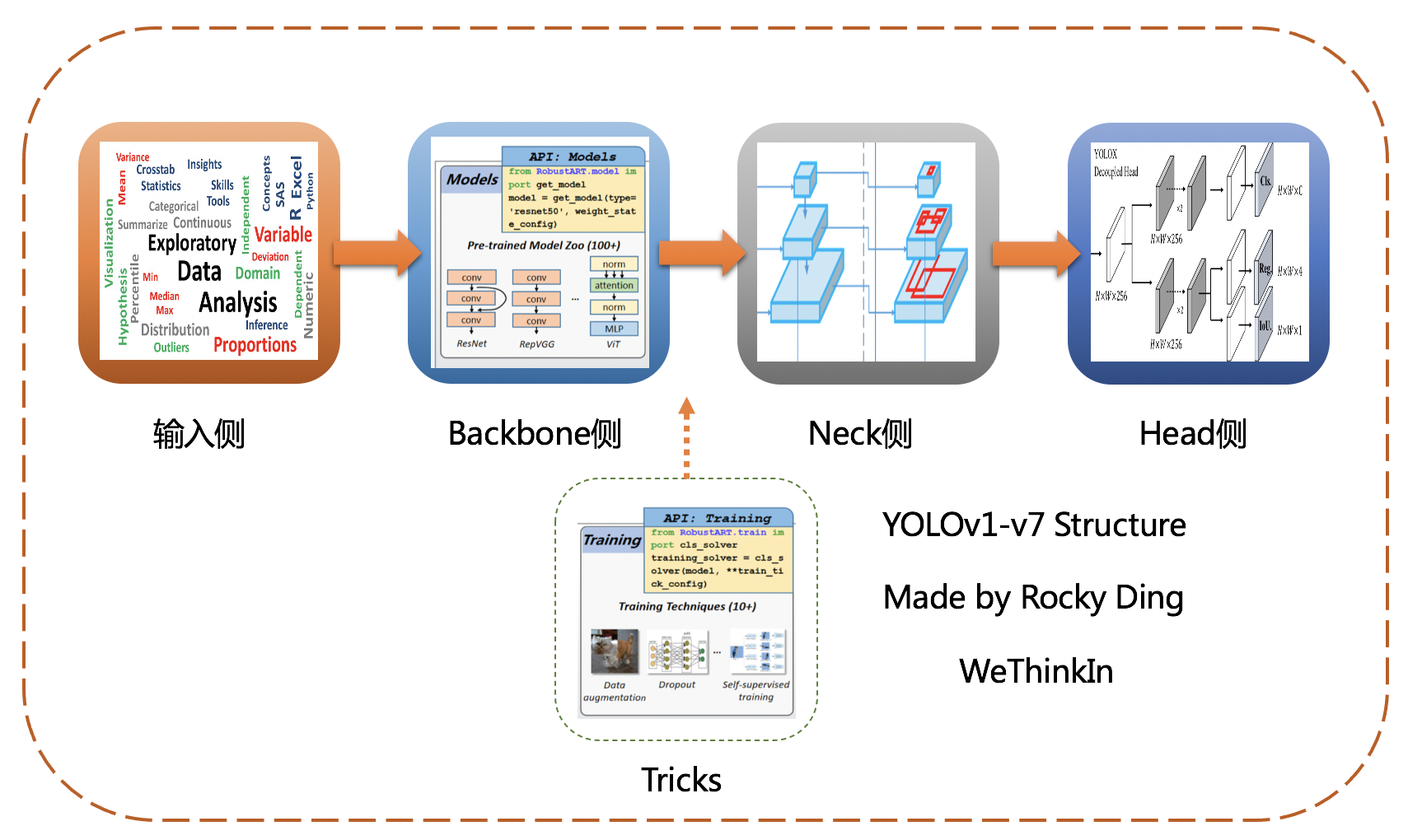
【一】YOLO系列
【二】YOLO系列中输入侧结构的特点
YOLO系列中的输入侧结构主要包含了输入图像,数据增强算法以及一些预处理操作。 输入侧可谓是通用性最强的一个部分,具备很强的向目标检测其他模型,图像分类,图像分割,目标跟踪等方向迁移应用的价值。 从业务侧,竞赛侧,研究侧等角度观察,输入侧结构也能在这些方面比较好的融入,从容。
【三】YOLOv1 输入侧解析
YOLOv1的输入侧有着朴素的逻辑,做的最多的工作是调整输入图像的尺寸以支持对图像细粒度特征的挖掘与检测。 同样的,YOLO系列的grid逻辑(“分而治之”)也从输入侧开始展开,直到Head侧输出相应结果。
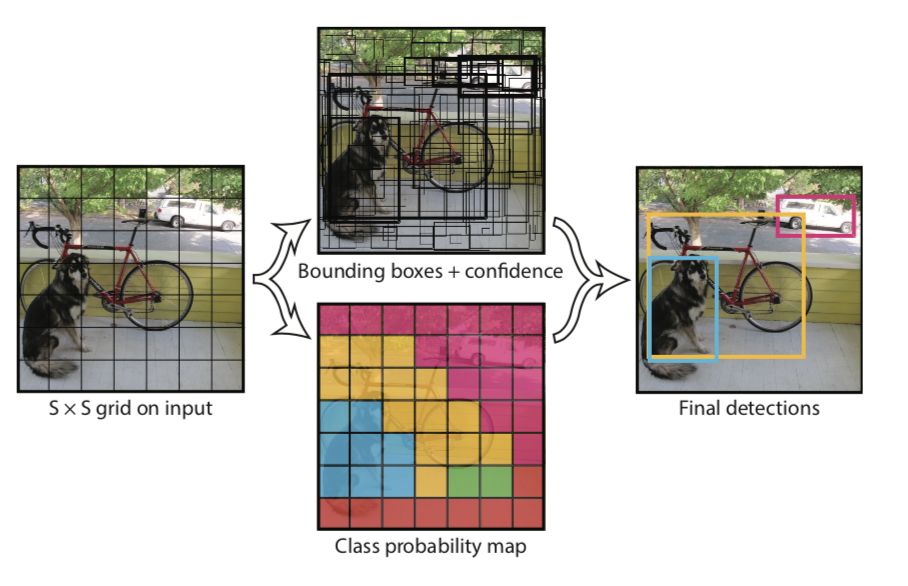 YOLOv1整体结构
YOLOv1整体结构

 虽然综述读起来累些,但多读综述有利于知识体系的梳理。而且NLP领域的综述读多了会发现,很多优化方法都是相通的,也能提供一些新的思路。
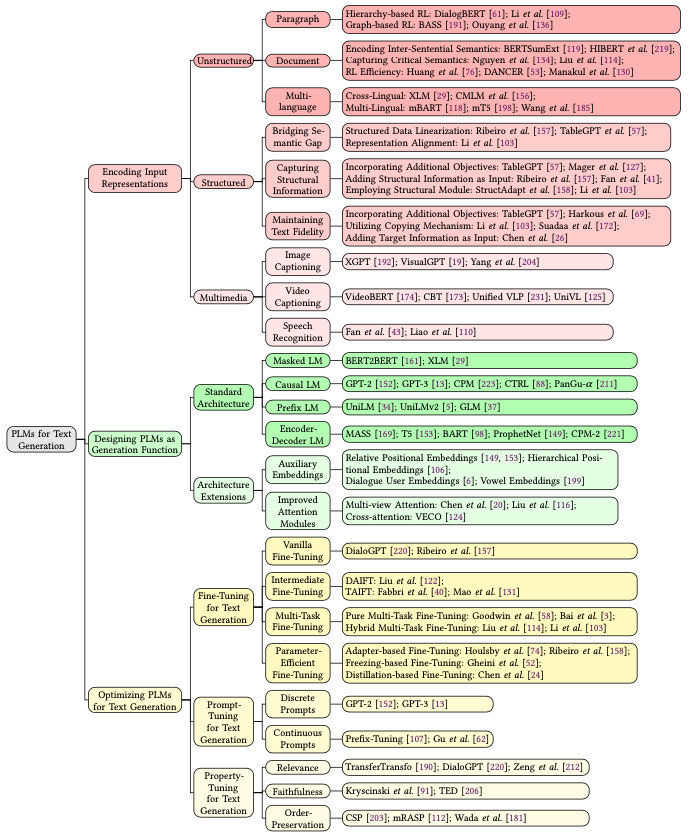
这篇文章从把文本生成的方法分成了三类:输入编码、模型设计、优化方法。同时也从数据、模型、优化层面给出了下面我们就顺着文章的思路,梳理一下最近几年文本生成领域的进展。
虽然综述读起来累些,但多读综述有利于知识体系的梳理。而且NLP领域的综述读多了会发现,很多优化方法都是相通的,也能提供一些新的思路。
这篇文章从把文本生成的方法分成了三类:输入编码、模型设计、优化方法。同时也从数据、模型、优化层面给出了下面我们就顺着文章的思路,梳理一下最近几年文本生成领域的进展。